突然ですが本ってかさばるし、重いですよね。でも、「また読むかもしれない」と思うとなかなか捨てにくいものです。
今までも引っ越しや部屋の模様替え等のタイミングで「もう読まない!」という本を厳選し古書店や資源ゴミ回収に出したりと少しは減らしてきました。が、しかし「やっぱり読みたくなった!」と何度買い直したことか。
自室に収まりきらない本は、倉庫や実家に分散して置いているのですが、距離的に離れた場所に置いた本は探している時に読めません。読みたい時に読めないのでは意味が無いと思うのです。
というわけで書籍の電子化に挑戦してみました。長くなりましたので、3編に分けています。
書籍を電子化し検索できるようにする <– イマココ
電子化した書籍を全文検索する(windows編)
電子化した書籍を全文検索する(Linux)
書籍の電子化って?
ネットでは「自炊」と書かれる事もあります。書籍を「スキャナ」という機械で読み取り、画像やPDF等の電子データに変換することです。
スキャナにかける時は、書籍をバラバラに解体してしまいますから、電子化した後の書籍は紙ゴミになります。メルカリ等で売る方もいるそうですけど!
 ↑の状態で、100冊くらいです。
↑の状態で、100冊くらいです。
※ スタンド型スキャナを利用すれば、解体しなくてもスキャンする事ができます。しかし、全ページを手でめくりスキャンする必要がありますから、とても手間がかかる事は想像するに難くないでしょう。
画像やPDFファイルは、PCやタブレット、画面は狭いですがスマホ等で読む事ができます。紙をめくる「ぱらぱら感」はありませんが、タブレットやPCの中に保存しておけば良いので持ち運びがとっても楽です。
メリット
- お部屋が広くなる
部屋や倉庫を圧迫していた本が片付きます。 - 内容の検索ができる
誤認識してしまう事も多いですが、後述のOCR(光学文字認識)処理をする事で、本の中身を検索する事ができるようになります。 - 携帯性が向上する
分厚い本も電子データ化をすれば、タブレットに入れて手軽に持ち運ぶことができるようになります。ぼくは、通勤時間がわりと長いので、通勤時間が読書時間になりました。
デメリット
- 本棚を眺めて探すという事ができない
本がただの電子データになりますので、視認性が悪くなります。本棚に並べている時は、色やらタイトルのフォントなどでなんとなく探していると思います。しかし、電子ファイルでは、ファイル名から探すしかありません。アプリによっては、ファイルの最初のページを表紙として、本棚風に見せてくれるものもあります。 - 「ぱらぱらとめくりながら」目的のページを探せない
一度読んだ本で覚えていれば、この本のこの辺りに書いてあったハズ。等と考えながらページをめくり目的の箇所を探すと思います。PDFビューアはそれほど遅いわけではありませんが、それでも物理的に紙をめくるより、ずっと遅くなります。 - データの保管に注意が必要
紙の書籍ならば、なくす危険はほとんどありませんが、電子データの場合は、ストレージ障害に備え、多重にバックアップを取得しておく必要があります。
法的な問題は無いの?
自分の所有物を私的利用のために電子化する事はなんら問題はありません。
今から10年くらい前に電子化が流行した頃は、本の裁断とスキャンを行い電子データを納品してくれる「自炊代行サービス」がたくさん立ち上がりました。
しかし、その後「自炊代行サービスは私的複製の範囲を逸脱している」との判断からほとんどの業者が店をたたんでしまいました。
この辺りをクリアにして、営業されている代行サービスもあります。
BOOKSCAN – 世界中の本好きのために –
未来BOOK – 本の電子化 –
この2社を検討してみました。しかし、電子化予定の冊数、送付手続き、オプションや定形外書籍に対する割増料金などなどを考慮にいれると「道具を購入」したほうが良いとぼくは判断しました。
書籍の電子化を検討し始めた時、スキャン予定の本は400+冊ありました。電子化したデータは、もちろんOCR処理を施したいので追加料金が発生します。
100~200円/冊+100円/冊(OCR料金) = 200~300円/冊となります。
400冊の電子データ化を業者にお願いすると8~12万円かかってしまう計算になります。それならば、道具を購入したほうが安いですね。
必要な道具
スキャナ
書籍を解体したページを電子化する為の機械。これが無いと始まりません。
「フラットヘッドタイプ」「シートフィードタイプ」「スタンドタイプ」等、いくつかの種類があります。
「自炊」では、書籍を解体してスキャンを行うので「シートフィードタイプ」のスキャナを利用します。
自炊派の定番は、富士通のScanSnapシリーズ。高価ですが評判が良いようです。
ぼくが購入したのは、ESPONのDS-530。WIFIは不要でしたので、この機種を選択しました。1分間に35枚のスキャン速度も魅力です。
裁断機
書籍を解体する時に、製本されている背中部分をばっさりと截断します。カッター等で切断しても良いのですが、処理する書籍が多い場合は、しっかりとした裁断機があれば安全に手間もかからず作業できます。
本をきっちりズレが無いように裁断する必要がありますから、しっかりとしたズレない裁断機を購入しました。高価ですが買って良かったと思っています。
未使用時はコンパクトに収納できるところもポイントが高いです。
カッター
裁断機で一度に切断できる枚数には制限があります。上で紹介した裁断機では100枚程度を推奨しています。100枚ということは、200ページですね。一般的な書籍は、300ページ程度はあると思いますので、裁断機にかける前処理として、裁断可能な枚数まで解体する必要があります。
この解体作業には、大型刃と円形刃の2種類のカッターがあると便利です。
ハードカバー書籍を解体するのには、こちら。
表紙を切り出すのには、これを使っています。
カッティングマット
厚紙などを引いて作業してもいいのですが、ずれなく安全なカッティングマットも準備しておくとGoodです。
金属製定規
カッターの刃が当たっても削れたりしない物なら問題ないでしょう。
アル助は、裏に滑り止めがついていてるし、カッター用の面もあったりしてお勧めです。
OCRソフト
OCRツール(画像から文字を起こすツール)は、大抵のスキャナに付属していると思います。
※ EPSON DS-530には「読んde!!ココパーソナルVer.4」が付属しています
横書き文字は案外良い精度で文字を認識してくれていたのですが、縦書き文字は、誤認識率が高くて利用を諦めました。
結局単体のOCRソフトウェアとしてPanasonicから発売されている
「読取革命Ver.15」を購入して利用しています。
が、しかし、まずは付属のツールを試してみるのが良いと思います。
総額
8万円くらいかかってしまいました。
最低限スキャナのみ(約4万円弱)でもはじめられます。
書籍の電子データ化
書籍の電子データ化を行うのには、以下の手順をふみます。慣れると大体10分/冊 程度の作業です。
- 書籍のスキャン準備
- 裁断機の能力以上の枚数(ページ)な場合は、いくつかに解体します
Durodex 200-DX推奨の、100枚程度分割します - 製本されている背中部分を裁断する
あまりギリギリで切らず、多めに切るときれいに裁断できます - カバーを切り取る
ぼくの場合は、表紙をページと同じサイズに切り出しています。
切らずに長い画像としてスキャンする事もできますから、切断したくない場合は、この作業は飛ばします。
- 裁断機の能力以上の枚数(ページ)な場合は、いくつかに解体します
- スキャナにかける
- 一度に読み込める枚数をスキャナにセットする
この時、きちんと裁断できていること。ページに糊が残り、くっついていない事を必ず確認すること。特に、カラーページの前後に糊が残りやすいようです。 - PDFとして保存する
画像として保存する方もいらっしゃるようですが、ぼくはOCRをかけて「検索可能なPDFファイル」を作りたいので、PDFとして保存します。
- 一度に読み込める枚数をスキャナにセットする
本を裁断する
スキャナで読み取れるように、書籍の背中部分を切り落とし全てのページを一枚づつの紙にします。
ハードカバーの書籍を分解してスキャンするところまで写真を貼ってみます。
まずは、裁断準備
 まずは、カバーを外してページサイズに切り出します。
まずは、カバーを外してページサイズに切り出します。
大体の大きさで問題ありません。
 次は、厚紙でできている表紙と裏表紙を切り取ります。これは、大型カッターで作業を行います。
次は、厚紙でできている表紙と裏表紙を切り取ります。これは、大型カッターで作業を行います。
なんとなく罪悪感を覚える作業です。
 本体を裁断する為に分解します。
本体を裁断する為に分解します。
 100ページ単位で3分割してみました。
100ページ単位で3分割してみました。

いよいよ裁断
裁断機は、こんな感じにコンパクトに収納できます。
 裁断する時に、背中ギリギリを切るとのり付け製本されている書籍で、ページに糊が残り複数ページがくっついた状態になることがあります。
裁断する時に、背中ギリギリを切るとのり付け製本されている書籍で、ページに糊が残り複数ページがくっついた状態になることがあります。
あまりギリギリを切らないで、大胆に切ってしまいましょう。電子データでは、余白のサイズはあまり気になりません。
 セットしたら、ハンドルを両手で下げる。これだけできれいに裁断完了です。カッターならば、定規を当ててズレないように力を入れて切っていく必要があります。裁断機を購入して良かったと感じる瞬間です。
セットしたら、ハンドルを両手で下げる。これだけできれいに裁断完了です。カッターならば、定規を当ててズレないように力を入れて切っていく必要があります。裁断機を購入して良かったと感じる瞬間です。

スキャナにセット
一度にスキャンできる枚数は、機種によって異なると思います。ぼくの購入したDS-530は、紙の厚さにもよりますが、大体120ページ(60枚)程度は一度にスキャンする事ができます。

スキャナのパラメータ設定は、何度かスキャンをしてみて、自分好みの値を決めるのがベストだと思います。が、ぼくには、それほどのこだわりはないので
-
- 高解像度(600dip)でスキャン
- カラーベージは、カラーの自動設定
- 白黒ページは、グレースケールの自動設定
この設定だけを変更しました。
ファイルをどのように分類するか問題
たくさんのファイルが1つのフォルダに置かれると視認性が悪くなります。これをどう整理するか?というのは、みんな頭を悩ませているのではないでしょうか。
方法は、大きく2つあるとおもいます。
-
- ファイルをtag管理する
- フォルダを分類別に作成し、その中にファイルを設置
Macでは、tagで分類するのが一般的なのかな?windowsでは、階層フォルダを作成する人が多い気がします。
ぼくはwindowsなのでフォルダで分けることにしています。
フォルダの分類について
では、分類方法は?まず思いつくのが日本十進分類法でしようか。しかし、図書館を作るわけではありません。自分が読む本は自然とジャンルが偏ると思います。なので、自分の中のジャンル分けをするのが使いやすいかなと思っています。
ぼくはオカルト本が多いので、オカルトの中で、古代文明/UFO/陰謀/超常現象 などと掘っていっても良いわけです。
なにはともあれ、分かりやすいのが一番です。
ファイル名の付け方について
ファイル名 = タイトル がシンプルで良いと思いますが、名前の重複が発生します。今、400冊程度でも重複が発生しました。
サブタイトルまで含めてファイル名にすると良いのかもしれません。あとは、著者名を入れるのも良いアイディアだと思います。
[田口ランディ]オカルト.pdf
[森達也]オカルト-現れるモノ_隠れるモノ_見たいモノ.pdf
OCR処理
OCRとは、Optical character recognitionの略で日本語だと光学文字認識となります。要するにスキャナで読み取った画像から、文字起こしをしてくれるツールです。
マンガは絵がメインですから画像でもなんら問題は無いと思います。しかし、普通の書籍は文字がメインコンテンツですから、画像だけではなく文字データとしての電子データ化まで行う事で利用価値が増します。
ひらたくいえば、内容の検索ができるかどうかという事。書籍の内容を検索できたら便利です。Kindleに代表される電子書籍で実現できている事を「自炊」でも実現したくなるのは当然の事です。
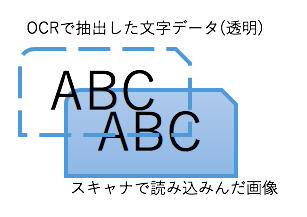
スキャン画像から検索可能なPDF作成の仕組み
スキャナで読み取ったデータは画像イメージです。それをPDF化しても、画像をPDF形式で貼り付けているにすぎません。
文字で検索をする為には、元々の画像を背景にして、OCR処理した結果のテキストデータを「透明なレイヤーに載せて」1つのPDFファイルとして結合する作業が必要です。
マニュアルでは、「透明PDF」、「透過PDF」、「透明文字PDF」という用語で説明される事が多いようです。
OCRツール
「シートフィーダタイプ」のスキャナは、書類等のスキャンを目的に販売されていますから、ほとんどのスキャナ製品にOCRツールが付属しています。Epson製のスキャナには、「読んでde!!ココ」が付属しています。
ぼくは単体製品として売られている「読み取り革命」を利用していますが、最近ではOSSのOCRツールもかなりの精度で認識できるそうです。
Tesseract Open Source OCR Engine (main repository)
読み取り革命
読み取り革命では、付属の「フォルダウォッチャー」というツールを利用する事でOCRのバッチ処理が可能です(他のツールでも可能かもしれません)。これがとても便利で、寝る前にセットしておけば、寝てる間に処理が終わっています。(小説で5分/冊, 雑誌で10分/冊)
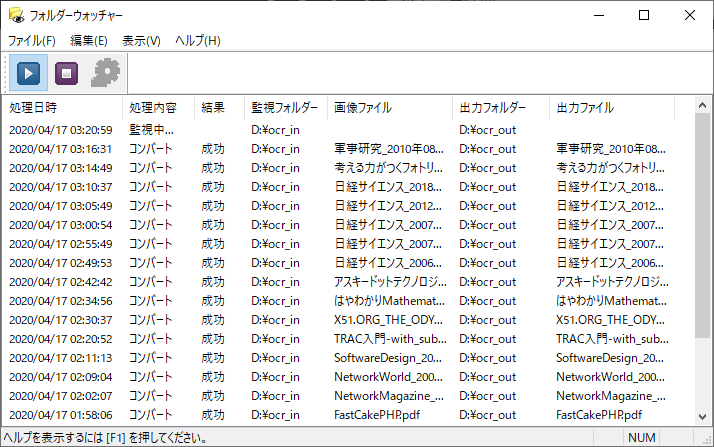
本の内容を検索してみる
裁断→スキャン→OCR処理と一連の作業が完了しました。早速、電子化の便利さを実感してみましょう。
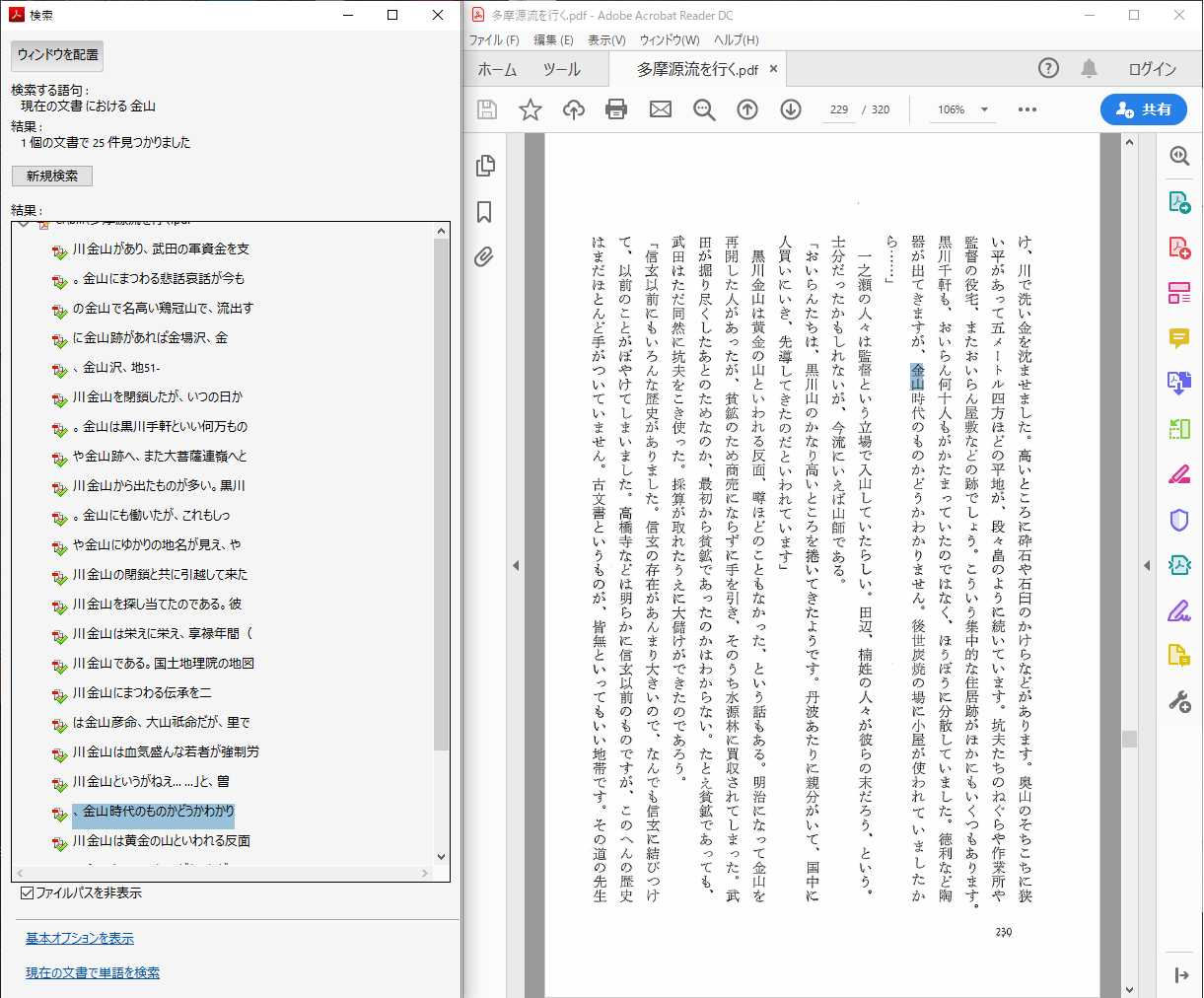 「金山」というキーワードで検索をしました。左のウインドウに「金山」を含む文が表示され、クリックすると該当ページが右ウインドウに表示されます。
「金山」というキーワードで検索をしました。左のウインドウに「金山」を含む文が表示され、クリックすると該当ページが右ウインドウに表示されます。
すばらしい。大満足です。
PDFツール
最近は、PDFを閲覧するだけならばブラウザで用が足ります。しかし、専用ツールには、他にも様々な便利機能があります。マーカーを引けたり、注釈、ペンに対応していれば手書き文字を追加する事もできたりします。
いくつかインストールして手に馴染むツールを探してみると良いかと思います。
- Adobe Acrobat Reader DC
本家AdobeがリリースしているPDFリーダ - Foxit Reader
最近流行りのPDFツール - PDF-XChange Viewer
(開発は終了しています) - PDF-XChange Editor
1画面2ページ表示モードで左右のページを入れ替えることができます。
残念ながら、2020.04の現行バージョンでは、縦書きPDFの内容検索に失敗してしまいます。※ バグレポートを提出してIssue Ticketを発行してもらいました
2022年11月28日リリースの9.5.365.0でこの不具合は修正されました!
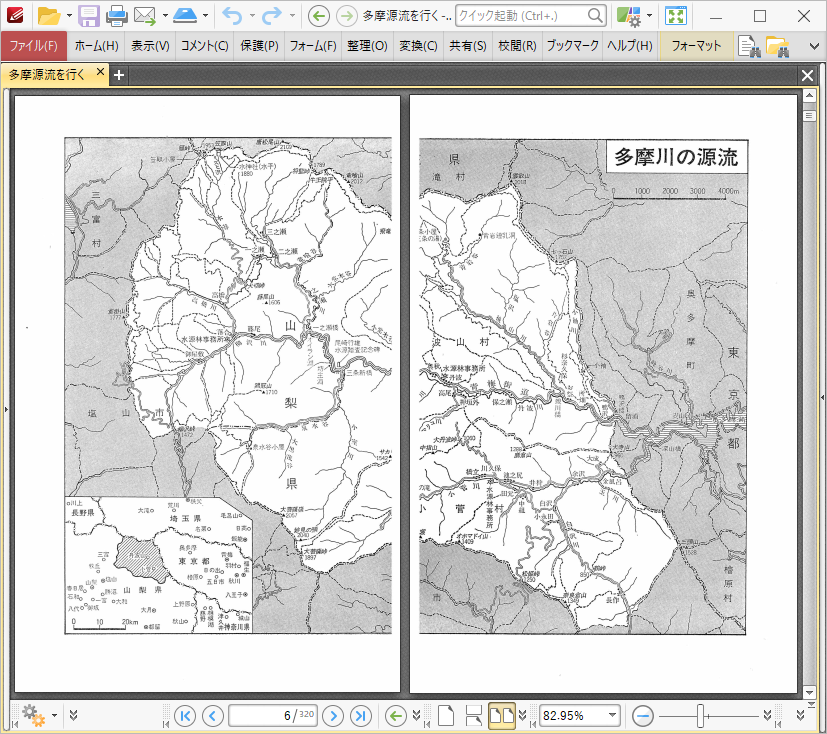
縦書きの日本語の書籍は右綴じです。しかし、右綴じ書籍をスキャンしたPDFファイルを1画面2ページモードで表示すると、大多数のPDF表示ツールでは左綴じを仮定してページの配置を行ってしまいます。
PDF-XChange Editorならば、左右のページを入れ替えることで、右綴じでも左綴じの書籍でも違和感なく表示する事ができます。
右綴じ書籍をAdobe AcrobatReaderDCで表示した場合
PDF-XChange Editorで左右ページを入れ替えた場合
次のステップ
ここまでの作業で、書籍のスキャン後に電子化し内容の検索ができるようになりました。これだけでも十分便利なのですが、全文検索システムを導入する事でキーワードを入力し、目的の書籍リストが表示されるようにできれば、もっと便利になるはずです。
次は、全文検索システムを導入してみたいと思います。