前回の投稿では、windows10の機能を利用して、全文検索システムを構築しました。incremental searchできるし、使い勝手は良いのではありますが、そのwindows上からでないと利用できないという弱点がありました。
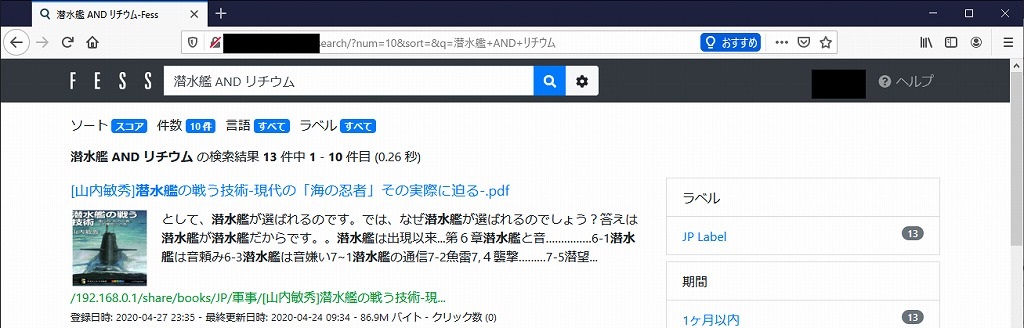
「タブレットやスマホでも検索したい」という欲求を満たすために、普段ルータとして稼働しているLinuxマシン上に全文検索システムを構築します。
書籍を電子化し検索できるようにする
電子化した書籍を全文検索する(windows編)
電子化した書籍を全文検索する(Linux) <– イマココ
Fessの運用メモ
Contents
Linux上に全文検索システムを構築
Fessというクローラー付の全文検索システムがOSSとして公開されています。Javaで書かれているのでWindowsでもMac上でも動くようです。
今回は、ルータとして使っているLinuxにインストール/設定を行いました。
ソースの他に、zip, rpm, deb, Docker形式のパッケージが用意されており、日本語のマニュアルの通りに進めていけばインストールは特に問題ないと思います。
オープンソース全文検索サーバー Fess (日本語サイト)
Fess Enterprise Search Server (GitHub.com)
想定環境(自宅の環境)
| OS | Debian 10 | |
| Fess | 13.6.3 | .debパッケージでインストール |
| Elasticsearch | 7.6.2 | .debパッケージでインストール |
| Apache | 2.4.38 | 内外からリクエストを受けるためにreverse proxyとして設定 |
| samba | 4.9.5 | LAN内でファイル共有のため |
fess起動前の確認事項
Javaバージョンの確認
システムに複数のJavaが導入されている場合、意図しないバージョンのJavaで起動されエラーが発生する事があります。
java-11が選択されていればOKです。
|
1 2 3 4 5 6 7 8 9 |
root@pooh:~# update-alternatives --config java There are 3 choices for the alternative java (providing /usr/bin/java). Selection Path Priority Status ------------------------------------------------------------ * 0 /usr/lib/jvm/java-11-openjdk-amd64/bin/java 1111 auto mode 1 /usr/lib/jvm/java-10-openjdk-amd64/bin/java 1101 manual mode 2 /usr/lib/jvm/java-11-openjdk-amd64/bin/java 1111 manual mode 3 /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java 1081 manual mode |
システムワイドな設定を変更したくない時は、/etc/default/fess に JAVA_HOMEを記述すれば、systemdから起動される際に 記述したJAVA_HOME で起動されます。
apacheでreverse proxy
Fessは、デフォルト状態でlocalhost:8080をListenします。直接外部へ晒すのは怖いので、reverse proxyを設定します。自宅環境では、すでにapache2が動いてるのでそのまま使いました。
reverse proxyの設定は、CSSなどのstatic pathがあると設定が面倒なので、今回は、virtualhostで作成しました。内側、外側用にDNS A-RRを設定して ServerAliasでどちらで来ても表示できるようにします。
許可したネットワーク以外からのアクセスには、Basic認証をかけています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
<VirtualHost *:80 > ServerAdmin root@example.com ServerName fess.example.com ServerAlias fess.intra.example.com DocumentRoot /home/www/fess.example.com/html/ ErrorLog /home/www/fess.example.com/logs/error.log CustomLog /home/www/fess.example.com/logs/access.log combined <Directory /home/www/fess.example.com/html/> Require all denied </Directory> # Fess ProxyRequests Off <Location /> Authtype Basic AuthName "Auth" AuthUserFile /home/www/fess.example.com/conf/.htpasswd Require valid-user Require ip 192.168.0.0/23 Require ip xxx.xxx.xxx.xxx/32 ProxyPass http://127.0.0.1:8080/ ProxyPassReverse http://127.0.0.1:8080/ </Location> </VirtualHost> |
Elasticsearchのstatus確認
Elasticsearchのcluster statusが”全てgeenではない場合” 、fessの初期起動に失敗する事がありました。
|
1 2 3 4 5 |
# curl -Ss -XGET 'localhost:9200/_cluster/health?pretty' | grep -w status "status" : "yellow", # curl -Ss -XGET 'localhost:9200/_cat/indices?pretty' | grep -i yellow yellow open .elastichq GTgPQsE-RDSoxuxu-wDXVg 1 1 1 0 6.4kb 6.4kb |
yellow状態となっているindexがある場合は、問題を解消し cluster状態を greenにしておきましょう。fessの初期起動時以外ならば、yellow状態でも、起動、再起動は問題ありませんでした。
|
1 2 |
# curl -Ss -XGET 'localhost:9200/_cluster/health?pretty' | grep -w status "status" : "green", |
fessの設定変更
処理できるファイルサイズを増やす
初期状態では、10MB(10485760)以上のファイルは処理しない設定値になっています。自炊した書籍データは、平均150MBですので、この値を引き上げました。少し大きめの500MB(524288000)にしました。
/usr/share/fess/app/WEB-INF/classes/crawler/contentlength.xml
|
1 |
<property name="defaultMaxLength">524288000</property><!-- 500M --> |
処理するファイルサイズを大きくした場合は、heapメモリサイズも増やします。Javaのチューニングはよくわからないのですが、Out Of Memory例外が発生したら少し大きくしていく感じでしょうか。最終的に最大heapサイズを4GBで運用しています。※使えるメモリ量と相談して決めること。
/etc/fess/fess_config.properties
|
1 2 3 4 5 |
-Xmx512m \ となっている箇所を -Xmx4g \ に書き換えます。 |
/etc/default/fess も修正しておきます。
|
1 2 3 |
# Heap Memory #FESS_HEAP_SIZE=512m FESS_HEAP_SIZE=4g |
fessの起動
パッケージでインストールすると、systemd の設定ファイルが配置されました。
|
1 2 3 4 |
# systemctl daemin-reload # systemctl enable fess # systemctl start fess # systemctl status fess |
初期起動時は、Elasticsearchにindexを作成します。作成完了までは、しばらく時間がかかります。/var/log/fess/fess.log を監視してエラーが出ないか確認しましょう。
エラーが発生せずに起動したら、 ブラウザでアクセスします。
遭遇したエラー
ブラウザでアクセスすると404が返る
これには悩みました。
404エラーは、fessがElasticsearchへの接続に失敗したり、存在するはずのindexが見つからない場合に発生します。
うちの環境では、元々Elasticsearchが稼働していましたので、fessはそこを利用するように設定をしました。が、cluster status が yellowのindexが多数存在していてその結果、fessが一部のindex作成に失敗していました。
cluster statusを全てgreenにした後は、fessは正常に起動しました。
こちらを参照
ファイルシステムを直接指定するとfessがファイルが見つけられない
Windowsからsamba経由でファイルを設置したのが原因のような気がするのですが、fessが日本語名前のファイルを見つけられませんでした。samba経由で見えるファイル名とファイルシステム上のファイル名が異なってしまうのです。
該当ファイルは、samba経由以外からのアクセスは想定していないので、Fessもsamba経由でクローリングさせる事にしました。
samba経由でクロールするとなにも設定せずに、検索結果のリンクから直接文書を開くことができるようになります。
Fessの設定(Web UIから)
adminのパスワード変更
ローカルでしか使わないから等という理由があっても、デフォルトのパスワードのまま運用すべきではありません。
パスワードを変更するか、別ユーザにadmin権限を付けてから、削除する方向で。
クローラの設定
なにはともあれ、クローラを作成して、Fessに文書の内容を読み込ませましょう。[クローラ -> ファイルシステム] とメニューをたどり、新規作成をします。
設定する項目はこれくらい。残りはデフォルトで問題ないと思います。
| パス | samba経由の場合 smb://<IP or 名前>/ディレクトリ/ |
| 深さ | ディレクトリを何階層降りるか |
| 最大アクセス数 | 勘違いしやすいのですが、クロールしたい文書ファイルのmax limitということです。
クロール対象にしたいファイルが100個あるのならば、100以上を指定します。 |
sambaへの接続設定
sambaへの接続に認証が必要なら、[クローラ -> ファイル認証 -> 新規作成]で、接続設定を行います。
スケジューラの設定
[システム -> スケジューラ -> Default Crawler] で設定します。
スケジュールは、cronの書式で記述します。左から「分、時、日、月、曜日」です。
|
1 |
0 */6 * * * |
上記の場合は、毎日00:00, 06:00, 12:00, 18:00に実行されます。
画面下部に、「今すぐ開始 」ボタンがありますので、準備ができたらクローラを起動し、/var/log/fess/fess-crawler.log にエラーがでないか確認します。
クローリングログの情報確認方法
adminダッシュボードの[システム情報 -> クロール情報 -> セッションID]で、そのクローリングで取得した文書を確認できます。
全文検索
クローリングの正常終了したら、全文検索を実行する準備は完了です。
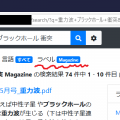
PCから検索をしてみます。
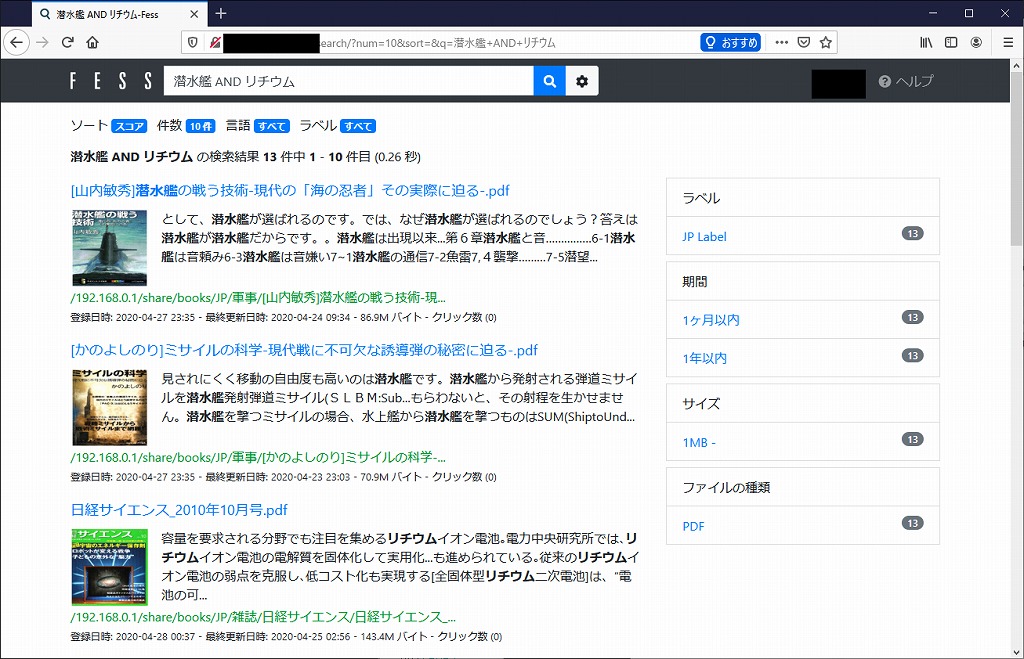 いい感じに検索できています。Fessは、スマホからも検索する事ができます。
いい感じに検索できています。Fessは、スマホからも検索する事ができます。

いい感じですね!
問題点とその対処方法
問題無く検索できているように見えましたが、何度か利用しているうちに、「検索結果に現れない文書がある」事に気づきました。もっとよく調べてみると、「縦書きPDF」の内容が検索結果に表れない事が多いという事がわかりました。
原因調査
OCR処理を施したPDFから抜き出したテキストデータは、Elasticsearchに格納されます。Elasticsearchに格納された「縦書きPDFファイル」から抽出されたテキストデータを確認すると、1文字毎に半角スペースが挿入されている事がわかります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
% curl -H "Content-Type: application/json" -XGET 'http://localhost:9200/fess.20200427/_search' -d ' { "_source": [ "content" ], "query": { "bool": { "must": [ { "match": { "_id": "40e9a64bd3a59f9bdd68cd3df0c3f21c794ac9d0292bce199002dc607674e573988a1aaefab4f691d2d61b6f0bfd68f1801f51fc04a6e962d897f5738770cbb0" } } ] } } }'| jq . { "took": 0, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 1, "hits": [ { "_index": "fess.20200427", "_type": "_doc", "_id": "40e9a64bd3a59f9bdd68cd3df0c3f21c794ac9d0292bce199002dc607674e573988a1aaefab4f691d2d61b6f0bfd68f1801f51fc04a6e962d897f5738770cbb0", "_score": 1, "_source": { "content": "ロ ロ ー グプ プ ロ ロ ー グ 哀 し き 「 伝 説 」 女 が ひ と り 、 泣 い て い た 。 一 九 八 三 年 。 そ の 女 性 は 関 東 地 方 の あ る 町 で 暮 ら し て い た 。 厳 格 で 真 面 目 な 仕 事 人 間 で あ る 父 親 。 優 し く 控 え め な 性 格 な が ら 、 シ ン の 強 さ を 持 っ て い る 母 親 。 そ ん な 典 型 的 な 中 流 家 庭 に 育 っ た 女 性 は 、 地 方 都 市 で は よ く 見 ら れ る よ う に 、 家 柄 や 学 歴 、 父 親 の 職 業 に 対 す る 信 頼 度 、 地 域 社 会 に お け る 評 価 な ど か ら 、 学 校 や 周 囲 の 推 薦 も あ っ て 、 そ の 地 方 で も 規 律 が 厳 し い こ と で 知 ら れ る 団 体 に 就 職 し た 。 父 親 が 団 体 の 関 係 者 で あ っ た こ と も 影 響 し た の は 間 違 い な い 。 そ の 団 体 は 全 国 組 織 で 、 本 拠 地 が 東 京 に あ る 。 女 性 が 勤 め た の は 、 そ の 県 の 中 心 都 市 に あ る 本 部 で あ っ た 。 7 D:20200430144018" } } ] } } |
このように、1文字毎に半角スペースが挿入されていると「潜水艦」を検索をかけた場合、Elasticsearch内には「潜 水 艦」と保存されている為にマッチしないのです。
原因は、PDFファイルのOCR処理の仕方(読み取り革命)にあるのかとも思ったのですが、違いました。縦書きPDFファイルをビュアーで開き、テキストをコピー&ペーストしても、半角スペースは挿入されていません。
対処方法
それならば、FessのPDFから文字データ抽出部分に問題があるのかもしれないと、ソースを眺めてみましたが、ぼくの能力ではよく解りません。
そこで、「Elasticsearchの中身を直接書き換える」という力業(笑)で対処する事にしました。
注意点
検索対象に日本語ではなく、例えば英文の文書が入っていた場合、半角スペースを削除すると元の文章の意味が解らなくなってしまいます。
ターゲット文書が日本語なのか、または、別な言語で書かれているのかを分類する必要があります。
ElasticsearchのQuery結果を見ると使えそうなフィールドがみつかります。
- lang
日本語の文書ならば、”ja”が入っている場合が多いのですが、必ず入っている訳ではなく、誤判定されて”en”になっている場合もありました。またその逆になっている事もあり、このフィールドを元にして判別するのは危険と判断しました。 - label
labelはクローラの探索PATHに、登録した正規表現でマッチする文書へlabel属性を付与できるFessの機能です。ユーザ側で完全に制御可能なので、この機能を利用して、日本語文書かどうかの判別をさせる事にしました。
運用でカバー
結局、以下のように運用する事で、「縦書きPDF」ファイルもFessで検索できるようになりました。
-
- 日本語の文書は、books/JP/ 以下に配置
- 英語の文書は、books/EN/ 以下に配置
- Fessの管理画面で、[クローラー -> ラベル] と進み、ラベルを作成
- Elasticsearchの中身を書き換え
- 新しいファイルを配置したら、クロール後に(4)を再実行
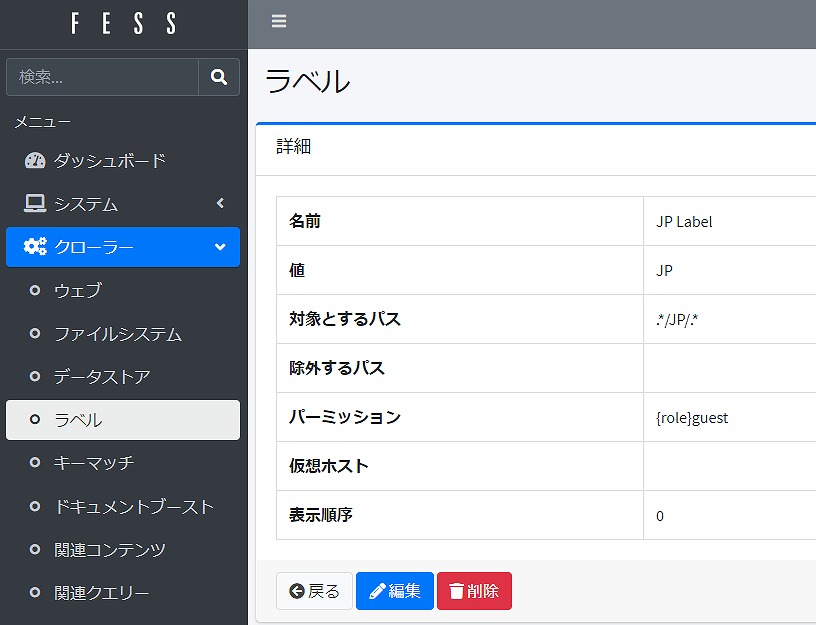
Elasticsearchの中身を書き換えるスクリプト
filetypeがPDF かつ labelがJPとなっているドキュメントのcontentsフィールドから半角スペースを削除します。
これが正しい解決法なのか不明ですが、とりあえずこの方法で検索できています。Elasticssearchは、フィールドを自由に追加できるので、今後処理済みかどうかのフラグを追加して効率化したいなーと思ってます。
idx_nameは、各環境で異なります(初めてFessを起動した日付)。環境に合わせて修正して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
from elasticsearch import Elasticsearch import re idx_name = 'fess.20200427' query_json = { "size": 5000, "query": { "bool": { "must": [ { "term": { "filetype": "pdf" } }, { "term" : { "label": "JP" } } ] } } } es = Elasticsearch() res = es.search(index=idx_name, body=query_json) r = res['hits']['hits'] for i in r: space_deleted_str = re.sub(r' ', '', i["_source"]["content"]) title = i["_source"]["title"] idn = i["_id"] es.update(index=idx_name, id=idn, body={'doc':{ 'content': space_deleted_str}}) print(title) |
最後に
2020年1月に「自炊セット」を購入して書籍の電子化を進めてきました。最初は、一度読んた本を整理できたらいいな位に考えていました。
しかし、全文検索システムを構築すると、すっかり忘れていた本に調べている事柄に関して記述があ見つかったりと、より有効活用できるようになりました。
これからはネット上でダウンロードした論文やハウツー文書なども登録してナレッジベースにできる良いなと思っています。