オープンソース全文検索サーバー Fess を使い始めてそろそろ10ヶ月ほど経ちました。いくつか試行錯誤を重ね運用が安定してきましたので、自分向けのメモとしてまとめてみました。
2021.07.13追記: debian系ディストリビューションでサムネイル画像が生成できない問題が 13.8.1 あたりから発生していましたので、その対策を書きました。
fessでthumbnail画像が生成されない問題
Contents
設定編
縦書きPDFが検索できない問題
Fess導入当初は、縦書きか?横書きか? でディレクトリを分けていました。
参照: 電子化した書籍を全文検索する(linux編)
しかし同じカテゴリ階層を2つ作らなくてはならず、ファイルのメンテナンスが煩雑になってしまう事に気づきました。
現在は「縦書きPDFのファイル名にマークを付け、Fessでラベルを付与する」という運用をしています。
具体的には、ファイル名の末尾に _v_ を付けるようにしました。
 この末尾に _v_ が付いたファイルをFessでラベル付けを行います。正規表現で下記のように指定します。
この末尾に _v_ が付いたファイルをFessでラベル付けを行います。正規表現で下記のように指定します。
 さて、これで縦書きPDFだけをelasticsearchから取り出せるようになりました。あとは、以前からの運用と同様に縦書きPDFのスペースを削除するスクリプトを実行すればOKです。
さて、これで縦書きPDFだけをelasticsearchから取り出せるようになりました。あとは、以前からの運用と同様に縦書きPDFのスペースを削除するスクリプトを実行すればOKです。
filetypeが’pdf’で、labelに ‘vertical’が付いているレコードに対してcontent内のスペースを削除します。電子化した書籍を全文検索する(linux編) に載っているコードとほとんど同じです(queryが違うだけ)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from elasticsearch import Elasticsearch import re idx_name = 'fess.20200427' query_json = { "size": 5000, "query": { "bool": { "must": [ { "term": { "filetype": "pdf" } }, { "term" : { "label": "vertical" } } ] } } } es = Elasticsearch() res = es.search(index=idx_name, body=query_json) r = res['hits']['hits'] for i in r: space_deleted_str = re.sub(r' ', '', i["_source"]["content"]) filename = i["_source"]["filename"] idn = i["_id"] print(filename) es.update(index=idx_name, id=idn, body={'doc':{ 'content': space_deleted_str}}) #print(title) |
同じディレクトリに縦書き/横書き関係なくファイルを設置できるようになったので、メンテナンス性も向上し満足です。
日本語フォルダをラベルの対象PATHに指定する
基本的にUNIXのディレクトリに2バイト文字は使いませんが、windowsから共有されるsambaフォルダには、日本語を使ってしまいます。
Fessで検索効率を高めるために”ラベル”を利用する事は多いと思うのですが、日本語名が付いたフォルダをラベル適用のパスに指定するところでハマりました。
Fessのフォーラムでは、日本語文字はURLエンコードを施して指定するという方法が紹介されていました。URLエンコードをするにはいろいろな方法があると思いますが、pythonでエンコードするならばこんな感じです。
|
1 2 |
$ python -c "import urllib.parse; print(urllib.parse.quote('雑誌'))" %E9%9B%91%E8%AA%8C |
“雑誌”をURLエンコードすると”%E9%9B%91%E8%AA%8C” になります。
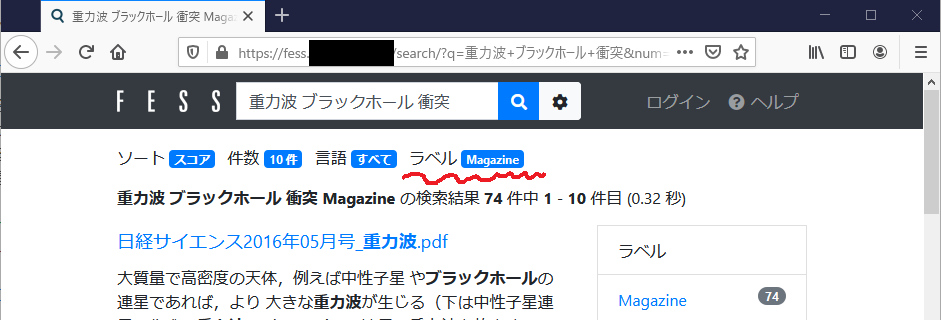
この名前が付いたディレクトリ以下のファイルすべてに”magazine”というラベルを貼りたいとします。普通に考えれば、下記画像のように指定すればいけそうな気がするのですが、全くラベルが付与されませんでした。なぜだろう?
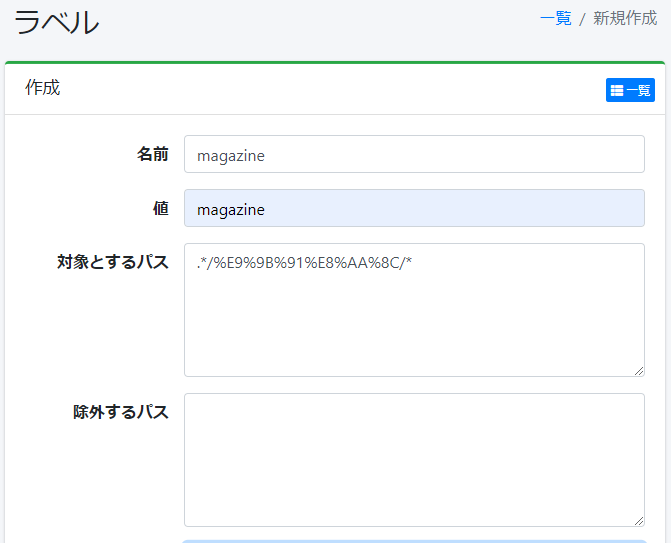 フォーラムを更に読んでいくと別な解決方法も載っており、そちらの方法ではうまくラベルが付与されました。
フォーラムを更に読んでいくと別な解決方法も載っており、そちらの方法ではうまくラベルが付与されました。

|
1 2 |
#DISABLE_URL_ENCODE .*/雑誌/.* |
対象とするパスの1行目に#DISABLE_URL_ENCODEを。
2行目に日本語入りで正規表現を書く事で意図したラベルが付与されました。
うちの環境ではラベル設定後、普通にクーロラージョブを開始すると問題なくラベルが付きました。しかしフォーラムでは、差分クローラを無効にしなくてはキャッシュされているファイルのラベルは更新されないとの記述もあり、うまくラベルがつかない時は、クローラーの差分更新をOFFにしてからジョブを走らせてみるのもよろしいかと。
運用編
Fessのバージョンアップ
Fessとelasticsearchのバージョンは、密接に関係しています。Fessがバージョンアップしたからといって、すぐにupgradeしてはいけません
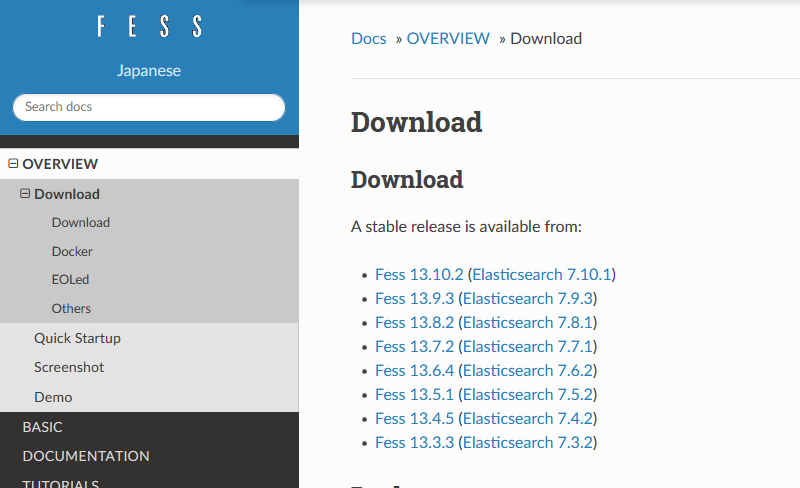
なにはともあれダウンロードページで対応するelasticsearchのバージョンを確認します。もし、Fess 13.10.2 が使いたいのならば、Elasticsearch 7.10.x が必要です。
逆に Elasticsearchを7.10.xへ上げたい場合は、Fessは 13.10.x を使わなければなりません。
 upgrade作業の流れは以下の通り。
upgrade作業の流れは以下の通り。
1) fessとelasticsearchを停止
|
1 2 |
# systemctl stop fess # systemctl stop elasticsearch |
2) fessとelasticsearchの設定ファイルをバックアップ
ソフトウェアのバージョンが上がると、今までの設定ファイルが使えなくなる事(設定項目の追加/削除等)や、パッケージに含まれている設定ファイルで上書きされてしまうこともあります。なので、upgrade前には、必ず設定ファイルを保存しておくと安心です。
設定ディレクトリをまるっとアーカイブしておいても良いと思いますし、どこかにコピーしても、必要なファイルだけバックアップ取るでも良いかと。
忘れがちなのが、fess配下の ‘app/WEB-INF/classes/crawler/contentlength.xml’です。ここでクロール対象にするファイルのサイズ等設定します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
_bk_date=$(date +%Y%m%d) cp -pi /etc/fess/fess_config.properties{,.$_bk_date} cp -pi /etc/fess/fess_env_crawler.properties{,.$_bk_date} cp -pi /etc/fess/fess_env_suggest.properties{,.$_bk_date} cp -pi /etc/fess/system.properties{,.$_bk_date} cp -pi /usr/share/fess/app/WEB-INF/classes/crawler/contentlength.xml{,.$_bk_date} cp -pi /etc/default/fess{,.$_bk_date} cp -pi /etc/default/elasticsearch{,.$_bk_date} cp -pi /etc/elasticsearch/elasticsearch.keystore{,.$_bk_date} cp -pi /etc/elasticsearch/jvm.options{,.$_bk_date} cp -pi /etc/elasticsearch/log4j2.properties{,.$_bk_date} cp -pi /etc/elasticsearch/elasticsearch.yml{,.$_bk_date} unset _bk_date |
3) elasticsearchのupgrade
先にelasticsearchをupgradeしていきます。必要とされるのが最新バージョンでは無い時はバージョンを指定してinstallです。
|
1 2 3 |
apt-get update apt list --upgradable apt-get install elasticsearch |
無事にelasticsearchが目的のバージョンに上がり、プロセスの起動も確認できたらfessに必要なelasticsearchのpluginをinstallしていきます。
※ elasticsearchの不要なバージョンが残っていたら混乱の元ですので不要ならば削除しましょう。
また、古いelasticsearch用のpluginが入っている場合は、先にremoveしてからinstallを進めます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
cd /usr/share/elasticsearch/bin/ ./elasticsearch-plugin remove elasticsearch-analysis-fess ./elasticsearch-plugin remove elasticsearch-analysis-extension ./elasticsearch-plugin remove elasticsearch-configsync ./elasticsearch-plugin remove elasticsearch-dataformat ./elasticsearch-plugin remove elasticsearch-minhash ./elasticsearch-plugin install org.codelibs:elasticsearch-analysis-fess:7.10.0 ./elasticsearch-plugin install org.codelibs:elasticsearch-analysis-extension:7.10.0 ./elasticsearch-plugin install org.codelibs:elasticsearch-configsync:7.10.0 ./elasticsearch-plugin install org.codelibs:elasticsearch-dataformat:7.10.0 ./elasticsearch-plugin install org.codelibs:elasticsearch-minhash:7.10.0 |
以上でelasticsearchのupgradeが終わりました。次はFessをupgradeします。
4) Fessのupgrade
各ディストリビューション用のパッケージが用意されていますので、環境にあったファイルを取得しinstallを行います。
|
1 2 |
wget https://github.com/codelibs/fess/releases/download/fess-13.10.2/fess-13.10.2.deb dpkg -i ./fess-13.10.2.deb |
先に取得しておいたバックアップファイルとの差分を確認して、修正箇所があれば修正していきます。新しい設定ファイルには、設定項目が追加されたり削除されているので単純にバックアップから戻すのではなく、修正が必要な項目を書き戻す感じで。
|
1 2 3 4 5 6 7 8 9 |
_bk_date=$(date +%Y%m%d) cd /etc/fess sdiff fess_config.properties{.$_bk_date,} sdiff /usr/share/fess/app/WEB-INF/classes/crawler/contentlength.xml{.$_bk_date,} : : : unset _bk_date |
修正が終わったらプロセスを起動します。
まずelasticsearchを起動しPortのListenされている事を確認。
|
1 2 3 4 |
systemctl start elasticsearch systemctl status elasticsearch netstat -nap | grep -w LISTEN | grep -E "\:9[23]" |
次にFessを起動します。
|
1 2 |
systemctl start fess systemctl status fess |
ログを確認し、エラー等出力されていない事を確認して完了です。
古いログが溜まる問題
Fessのログは、/var/log/fess/ 以下に配置されていると思います。実際にこのディレクトリ以下をみるとかなり古いログも消されずに残ってしまっています。
お仕事で利用されている方には、検索ログなど重要なデータなのかもしれませんが個人の趣味用に運用している場合は、必要なデータではありません。なにか問題が発生した時に中を見る程度なので、1週間分くらい保存されていれば十分です。
古いログを消すというのはサーバ運用ではよくある話で、こういう時は find コマンドです。
- 最終更新日から7日以上経った (-mtime +7)
- 通 常ファイル (-type f)を
- 消す (-exec rm -f {} \;)
というスクリプトを書いて
|
1 2 3 4 5 |
$ cat fess_delete_old_log.sh #!/bin/bash WORK_DIR=/var/log/fess find ${WORK_DIR} -type f -mtime +7 -exec rm -f {} \; |
rootのcronに仕込みます。
|
1 2 3 4 5 |
$ sudo crontab -l : : # delete old logs in /var/log/fess/ 15 2 * * * bash /somewher/fess_delete_old_log.sh |
最近のバージョンではlogを自動で圧縮してくれるので、findの条件をもう少し厳し目にして
- 一週間以上前に更新された圧縮済みのファイルを消す
(-type f -mtime +7 -name “*.gz” -exec rm -f {} \;)
にしても良いかもしれません。