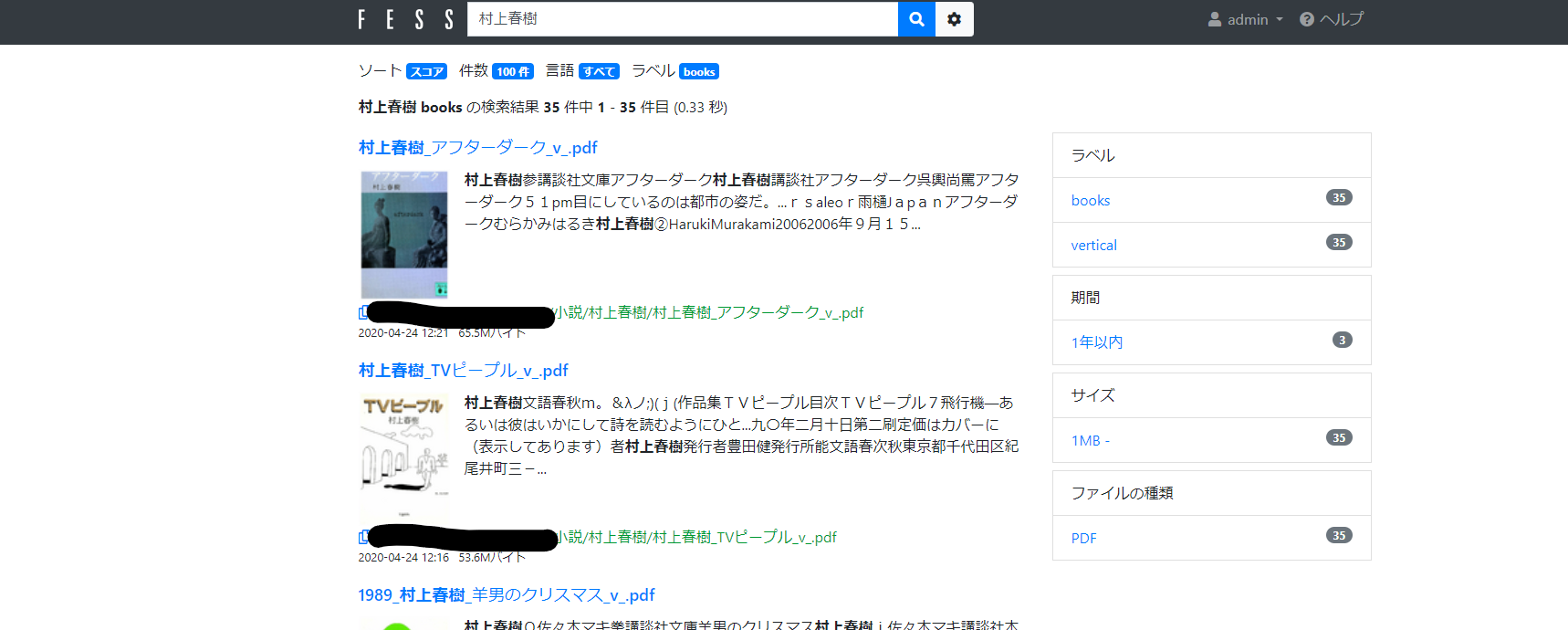
このblogで過去に何度かFessの運用メモを書いてきました。が、内容が古くなってしまったり、もう不要となったパッチ、より効率的な運用に変えてしまっている箇所もあり気になっていました。
今回、Fessのバージョンを上げた際にElasticsearchからOpenSearchへバックエンドを変更したのが良い機会と思い、Fessを使った全文検索システムの運用メモを整理し直しました。
はじめに
自炊したPDFファイルを自宅サーバに配置し、それらのPDFファイルを全文検索するシステムを Fess を使い構築しています。安定稼働し始め現状に不満がないと新しいバージョンがリリースされてもなかなかアップデートをする気分にならず、気づくと2年以上バージョンアップをサボっていました(もちろんFessは安定稼働していて、全文検索は調べ物の時便利に利用していました)
先日、久々にFessのページを訪れると最新バージョンは14.13.0と自宅サーバで稼働しているのバージョンよりかなり上がっていました(自宅サーバでは、13.15.3 2021.12.16リリースでした)。
マニュアルを軽く読んでいくと、最新バージョンのバックエンドにElasticsearchの名前が書かれておらず、代わりにOpenSearchがサポートされますとあります。ElasticsearchをOpenSearchへ置き換えなくちゃいけないのか。いろいろ変更がありそうだし少し悩んだのですが、丁度暇だったのでアップデートする事にしました。
通常、バックエンドを変更する時は、データの移動などの作業が発生すると思います。しかし、Fessで利用するデータは自炊したPDFファイルの内容です。またクロールすれば良いので、今回、データの移動は行いません。
OpenSearchとFessをクリーンな状態からインストールし、安定運用できるように設定するところまでをゴールとします。
想定環境
| OS | Debian 12 bookworm (Stable) |
| HTTP Server | apache2 2.4.59 |
| Java runtime | openjdk17 |
| Fess | 14.13.0 |
| OpenSearch | 2.13.0 |
- 自宅サーバでは、Debian12 Stableが稼働中
- 自宅内部ネットワークとインターネットに足を出していて、外部から接続可能
- OpenSearchへはHTTPで接続
- 内部利用なのでSSLは設定しない
- loopback:9200にbindさせる
- Fess
- loopback:8080にバインドさせる
- apache2でリバースプロキシをする
- ファイルシステムを直接参照してcrawlする
- 検索対象ファイル
- PDFとTXTファイルを対象とする
- 対象のPDFファイルはOCR処理をして透過テキストが埋め込まれていること
- 縦書きPDFファイルはファイル名の最後が _v_.pdf となっていること
例) 縦書き_v_.pdf というようなファイル名にしている
OpenSearch
OpenSearchは全文検索をするソフトウェアで検索エンジンと呼ばれています。Elasticsearchから派生したプロダクトでAmazonによりメンテナンスされています。ライセンス周りでもめて、個人利用ならばElasticsearchを利用可能ですが、FessのマニュアルにOpenSearchと書かれているので、OpenSearchをインストール/設定します。
インストール
基本的に、公式サイトのインストールガイドの通りに進めていけば特に問題は無いはず。
Java runtime 11 or 17が必要です。導入されていなければインストールが必要です。
|
1 2 3 4 5 6 7 |
# update-alternatives --list java /usr/lib/jvm/java-17-openjdk-amd64/bin/java # java --version openjdk version "17.0.11" 2024-04-16 OpenJDK Runtime Environment (build 17.0.11+9-Debian-1deb12u1) OpenJDK 64-Bit Server VM (build 17.0.11+9-Debian-1deb12u1, mixed mode, sharing) |
全てdebianパッケージでインストールを行うので、aptの各種設定をマニュアル通りに実施後にパッケージのインスートルを実施します。Debian packageは、install時に初期パスワードをコマンドラインで指定が必要です。
|
1 2 3 4 5 |
# apt-get update && sudo apt-get -y install lsb-release ca-certificates curl gnupg2 # curl -o- https://artifacts.opensearch.org/publickeys/opensearch.pgp | sudo gpg --dearmor --batch --yes -o /usr/share/keyrings/opensearch-keyring # echo "deb [signed-by=/usr/share/keyrings/opensearch-keyring] https://artifacts.opensearch.org/releases/bundle/opensearch/2.x/apt stable main" | sudo tee /etc/apt/sources.list.d/opensearch-2.x.list # apt-get update # env OPENSEARCH_INITIAL_ADMIN_PASSWORD=xxxx apt-get install opensearch |
今回導入するFess-14.13.0に対応するOpenSearchのバージョンは、2.13.xです。正しいバージョンがインストールされたか確認しておきましょう。
※ バージョンが異なっていたら、要求されるバージョン番号を指定してインストールします。
例) env OPENSEARCH_INITIAL_ADMIN_PASSWORD=xxxx apt-get install opensearch=2.13.0
|
1 2 |
# dpkg -l |grep -i opensearch ii opensearch 2.13.0 amd64 An open source distributed and RESTful search engine |
Fessで利用するPluginも導入してしまいます。導入するpluginとバージョンは、fessのバージョンによって異なるので、必ずマニュアルを参照すること。
|
1 2 3 4 |
# /usr/share/opensearch/bin/opensearch-plugin install org.codelibs.opensearch:opensearch-analysis-fess:2.13.1 # /usr/share/opensearch/bin/opensearch-plugin install org.codelibs.opensearch:opensearch-analysis-extension:2.13.1 # /usr/share/opensearch/bin/opensearch-plugin install org.codelibs.opensearch:opensearch-minhash:2.13.1 # /usr/share/opensearch/bin/opensearch-plugin install org.codelibs.opensearch:opensearch-configsync:2.13.1 |
設定
デフォルトの状態から修正する箇所はあまりありませんが
- ヒープメモリの最大値を変更。環境によって違うと思いますので良さげな感じで。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# diff -u /etc/opensearch/jvm.options{.orig,} --- jvm.options.orig 2024-01-17 14:01:05.461058550 +0900 +++ jvm.options 2024-01-17 15:07:45.040654854 +0900 @@ -20,7 +20,7 @@ # Xmx represents the maximum size of total heap space -Xms1g --Xmx1g +-Xmx8g ################################################################ ## Expert settings |
- loopbackにバインド
- fessに必要なpluginの設定 (configsyncの行)
- opensearchのセキュリティ設定を解除
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# diff -u /etc/opensearch/opensearch.yml{.orig,} --- /etc/opensearch/opensearch.yml.orig 2024-01-12 11:24:04.909900790 +0900 +++ /etc/opensearch/opensearch.yml 2024-01-16 00:15:16.396524905 +0900 @@ -53,6 +53,7 @@ # Set the bind address to a specific IP (IPv4 or IPv6): # #network.host: 192.168.0.1 +network.host: localhost # # Set a custom port for HTTP: # @@ -122,6 +123,10 @@ # #opensearch.experimental.feature.concurrent_segment_search.enabled: false +discovery.type: single-node +configsync.config_path: /usr/share/opensearch/data/config/ +plugins.security.disabled: true + ######## Start OpenSearch Security Demo Configuration ######## # WARNING: revise all the lines below before you go into production plugins.security.ssl.transport.pemcert_filepath: esnode.pem |
起動と確認
まずは、サービスの起動
|
1 2 |
# systemctl start opensearch # systemctl status opensearch |
設定ファイルの書き方を間違えなければ localhost:9200 で Listenされているハズです。
|
1 2 3 4 5 |
# netstat -nap| grep -w LISTEN| grep :9[23]00 tcp6 0 0 127.0.0.1:9300 :::* LISTEN 1127989/java tcp6 0 0 127.0.0.1:9200 :::* LISTEN 1127989/java tcp6 0 0 ::1:9300 :::* LISTEN 1127989/java tcp6 0 0 ::1:9200 :::* LISTEN 1127989/java |
curlコマンドでGETして確認します。このようにレスポンスが返ればOpenSearchのインストールは完了です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# curl -X GET http://localhost:9200/ { "name" : "hostname", "cluster_name" : "opensearch", "cluster_uuid" : "2QlBVQ-JSoC0IZ1C78oHNA", "version" : { "distribution" : "opensearch", "number" : "2.13.0", "build_type" : "deb", "build_hash" : "7ec678d1b7c87d6e779fdef94e33623e1f1e2647", "build_date" : "2024-03-26T00:13:13.172253920Z", "build_snapshot" : false, "lucene_version" : "9.10.0", "minimum_wire_compatibility_version" : "7.10.0", "minimum_index_compatibility_version" : "7.0.0" }, "tagline" : "The OpenSearch Project: https://opensearch.org/" } |
Fess
いよいよFessのインストールに入ります。FessもDebianパッケージでインストールしますので、公式マニュアル通りに進めれば躓くことは無いと思います。
インストール
- OpenSearchへプラグインのインストール
- OpenSearchへプラグインの設定追加
上記作業は、OpenSearchのインストール時に作業済みです。
次にgithubのリリースページからパッケージをダウンロードします。現在は4.13.0が最新なのでそれをダウンロードしてからインストールします。
余談ですがFessとOpenSearchのバージョンには依存関係がありますので、導入しようとしているバージョンのFessが現在稼働中のOpenSearchのバージョンと適合しているかどうかを確認してください。githubのreleaseページで確認できます。
|
1 |
# apt-get install ./fess-14.13.0.deb |
設定
localhost:8080 へバインドする
apacheで reverse proxyをしたいので、localhostへバインドさせます。
|
1 2 3 4 5 |
/etc/fess/tomcat_config.properties #tomcat.bindAddress=127.0.0.1 ↓ tomcat.bindAddress=127.0.0.1 |
おま環かもしれませんが、PATHの指定がおかしくて修正しました。
|
1 2 3 4 5 6 7 8 9 |
# diff -u0 /etc/default/fess{.orig,} --- /etc/default/fess.orig 2024-01-17 14:32:21.155148869 +0900 +++ /etc/default/fess 2024-05-03 00:30:02.824959044 +0900 @@ -11 +11 @@ -FESS_DICTIONARY_PATH=/var/lib/opensearch/config/ +FESS_DICTIONARY_PATH=/var/lib/opensearch/data/config/ @@ -17 +17 @@ -FESS_HEAP_SIZE=512m +FESS_HEAP_SIZE=8G |
check
fessを起動してエラーが出力されないことを確認します。エラーが出ていたら内容に従って設定を修正します。
|
1 2 3 |
# systemctl start fess # systemctl status fess # tail -F /var/log/fess/fess.log |
最近のopensearchは各種ファイルのpermissionが厳しめに変わっていて、fessがファイルを適切に読み込めないエラーを吐くかもしれません。その場合は、fessユーザのgroupにopensearchをいれてあげましょう。
|
1 2 |
# id fess uid=121(fess) gid=130(fess) groups=130(fess),997(opensearch) |
問題なく起動したらopensearchにfessがいくつかインデックスを作成します。インデックスの作成が確認できればfessインストールは完了です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
% curl -XGET 'http://localhost:9200/_cat/indices'|grep fess % Total % Received % Xferd Average Speed Time Time Time Current green open fess.suggest.20240429120003 VkrSMDQDSVCoTQb8S74bLA 1 0 58744 140642 25.8mb 25.8mb green open fess_config.related_content XcxVnKQaQoytoSM2dLdquQ 1 0 0 0 208b 208b green open fess_user.group OnkHDUYZRmu_5z9IdhOB4w 1 0 0 0 208b 208b green open fess_config.duplicate_host p1hnN8siQxS0ixd9vwGXhQ 1 0 0 0 208b 208b green open fess_suggest_array.fess OCH-turDQF6LirRFOmVksw 1 0 2 0 12.6kb 12.6kb green open fess.20240423 lquw1iIaSp2jg9e75gtozQ 5 0 1864 0 2.8gb 2.8gb green open fess_config.crawling_info_param lUlkBfPsROSrqHSWkSWHQg 1 0 11 0 6.2kb 6.2kb green open fess_config.file_config PItTUSjETIqFj0zxukJV0Q 1 0 1 0 8.1kb 8.1kb green open fess_user.user mEnxJw1nT1e5IGC9wllgzQ 1 0 2 0 10.7kb 10.7kb green open fess_config.key_match 6WrViwGbRbOv37IULTNSKg 1 0 0 0 208b 208b green open fess_crawler.queue rGsPDif1Q8Knnq6PN46lUA 10 0 0 0 1012kb 1012kb green open fess_config.elevate_word_to_label L3d2BjKiSayfJfMwOHv_ew 1 0 0 0 208b 208b green open fess_config.access_token P2TQzRKzQO2pRud17b0e_A 1 0 0 0 208b 208b green open fess_config.role_type GBy3a3uZSwCbnGktSnVbOQ 1 0 0 0 208b 208b green open fess_log.favorite_log hKk5wcAYQUGV7D9joPQ-cg 5 0 0 0 1kb 1kb green open fess_suggest_badword.fess QyUzCW81TZ-MPGFDl926GQ 1 0 0 0 208b 208b green open fess_suggest voxnazxGRSChsTIxARXVlA 1 0 1 0 6.9kb 6.9kb green open fess_config.job_log aqz627R-R1WcE1dGnOaxBQ 1 0 36 2 50.8kb 50.8kb green open fess_config.scheduled_job 04JO0fCeRLO8jchFmCszYQ 1 0 11 0 11.4kb 11.4kb green open fess_log.user_info GA4RhBKDT1WtS3Ik2-gfaA 5 0 2 0 16.8kb 16.8kb green open fess_config.failure_url OvGL310XTVKLbEYBCffZPQ 1 0 119 7 159.5kb 159.5kb green open fess_config.bad_word cKBGjFUiS5iR4JFstTCuog 1 0 0 0 208b 208b green open fess.202404251113 S2YlQNhaTG-wm25zGoZ45w 5 0 300 0 530.7mb 530.7mb green open fess_config.label_type qze02kq9T6a7112rKkU94w 1 0 9 0 60.6kb 60.6kb green open fess_log.search_log UF4707-XRKe954c9MuThhQ 5 0 51 0 6.5mb 6.5mb green open fess_config.file_authentication jHkVLc9AT4-hGJvVRB_Y0A 1 0 0 0 208b 208b green open fess_crawler.data gBR_hBjXTKSk7gvxSoWbdw 10 0 0 0 758.4mb 758.4mb green open fess_crawler.filter _wLddp-ZQkWV_Bvt-k21fg 10 0 0 0 2kb 2kb green open fess_config.crawling_info u5EyydLjQjeaDhSEl_44Nw 1 0 1 0 12.3kb 12.3kb green open fess_config.elevate_word s3Ez-_oNQiGtmOEuQkhmnw 1 0 0 0 208b 208b green open fess_log.click_log Wc2QYWeESlOLsSSqwRIe5Q 5 0 5 0 41.7kb 41.7kb green open fess_config.request_header KHSDXbW_SEOeZnefzlxUHw 1 0 0 0 208b 208b green open fess_config.web_config M2LI18qjTpS4dNMVVQqccw 1 0 0 0 208b 208b green open fess_config.data_config hmYgY6IqRJiT2C6-JHWp0w 1 0 0 0 208b 208b green open fess_suggest_analyzer LKCeWRG5RO-65EbfINvc-Q 1 0 0 0 208b 208b green open fess_user.role Rbx_GcPlQeiR6-GxAhqGZw 1 0 2 0 3.5kb 3.5kb green open fess_config.related_query _dxim0NIRw-XesMSfhaDgw 1 0 0 0 208b 208b green open fess_config.thumbnail_queue BlAFD75XSvKJIY2xGTL_2w 1 0 1325 1052 2.1mb 2.1mb green open fess_config.web_authentication SBqQn1FxTpyYERkoRqdwJw 1 0 0 0 208b 208b green open fess_config.boost_document_rule FsJcWgtzTcOQ5TgAR87_Og 1 0 0 0 208b 208b green open fess_config.path_mapping ZANJDGYLQQ6s5IdokDW9Bw 1 0 1 0 6.1kb 6.1kb |
チューニング
ヒープメモリの最大量を大きく
最適値は環境によって異なると思います、fessがメモリ不足のログを吐いたら大きくしていけばよろしいかと。
|
1 2 3 4 |
/etc/fess/fess_config.properties -Xmx512m ↓ -Xmx8G |
最大検索ファイルサイズを大きく
初期設定状態のfessでは10Mバイトまでのファイルしかインデックスしません。用途次第ですが、自炊した本をPDF化すると、大部分は50Mバイト以上のファイルとなります。ぼくがスキャンした本で最も大きかったのが600Mバイト位。なので、余裕をもって1Gバイトまで検索対象とするように設定しました。
|
1 2 3 4 5 |
/usr/share/fess/app/WEB-INF/classes/crawler/contentlength.xml <property name="defaultMaxLength">10485760</property><!-- 10M --> ↓ <property name="defaultMaxLength">1073741824</property><!-- 1G --> |
検索結果の表示数のデフォルトを変更
初期値では検索結果を10件づつ表示するようになっている。個人的に検索結果は100件くらい表示して欲しい。検索表示件数のデフォルト値を変更する。
|
1 2 3 4 5 |
/etc/fess/fess_config.properties paging.search.page.size=10 ↓ paging.search.page.size=100 |
trouble shoot
FessのTopページへアクセスすると 404 としか表示されない
Elasticsearch または OpenSearch 上にFessのインデックスが無い/足りない場合に発生しました。Fessのログを参考にしてなぜインデックスの作成に失敗したのかを調べ、原因を解消します。
ファイルシステムの直接クロールを試みるとファイルがあるのにみつからないと表示される
OSのlocaleが足りない事が原因かもしれません。うちのDebianでは、en_US.UTF-8 のみが有効になっていました。ja_JP.UTF-8 を追加(コメントを外す)してから、locale-gen を実行することで、fessが直接ファイルシステム上にあるUTF-8で書かれたファイルを参照できるようになりました。
|
1 2 3 4 5 6 7 8 9 |
$ cat /etc/locale.gen|grep -v ^# en_US.UTF-8 UTF-8 ja_JP.UTF-8 UTF-8 $ sudo locale-gen Generating locales (this might take a while)... en_US.UTF-8... done ja_JP.UTF-8... done Generation complete. |
ラベルの対象に日本語パスを指定すると認識されない
2つの方法があり、どれが正しいのがよくわからないのですが、うちの今の環境では、日本語文字列をURL ENCODEしてうまく動いています。
|
1 2 |
$ python3 -c "import urllib.parse; print(urllib.parse.quote('科学'))" %E7%A7%91%E5%AD%A6 |
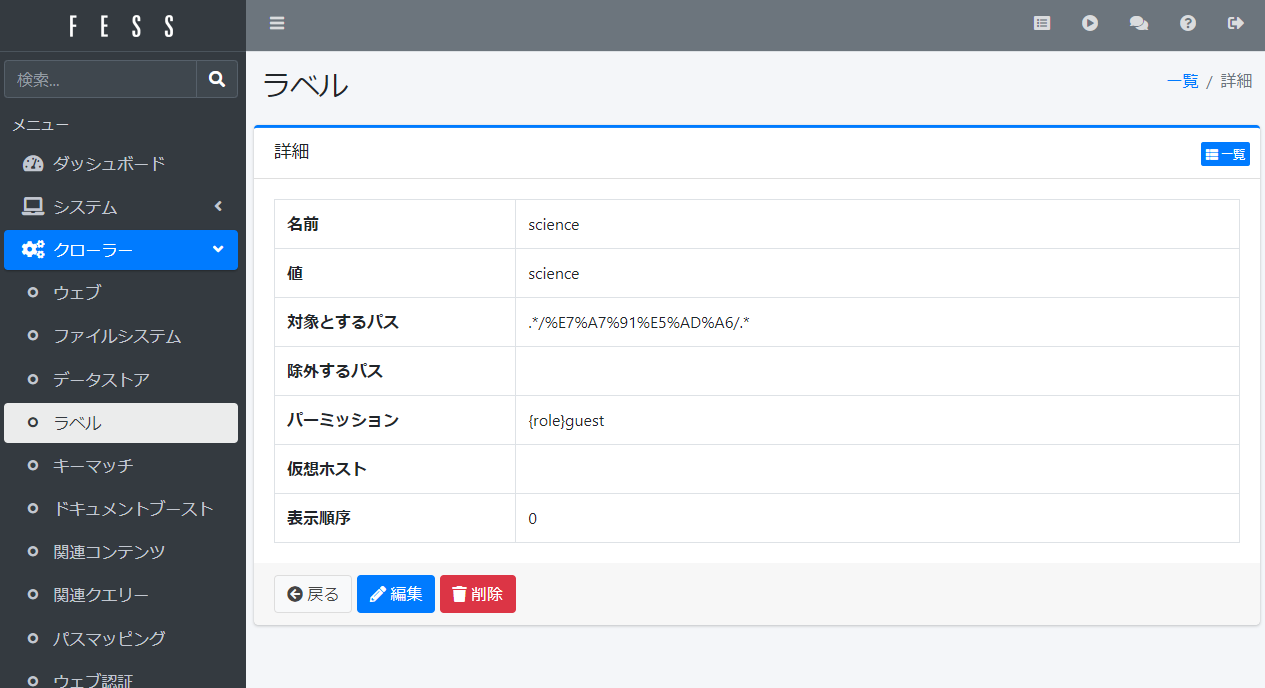
もうひとつの方法は、#DISABLE_URL_ENCODEという文字を直前に挿入することです。クロール対象がsambaでアクセスするファイルシステムの時は、この方法が上手くいっていました。
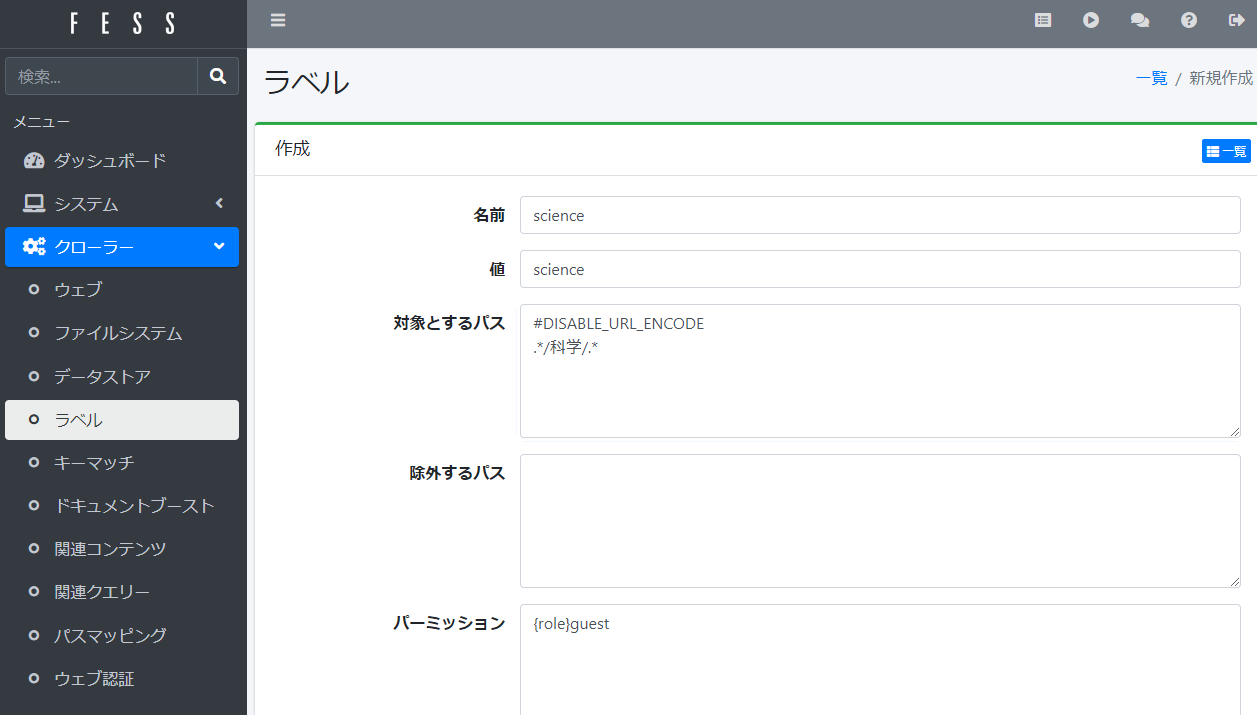
現在は、Debianが直接mountしているファイルシステム上にすべてのアーカイブが置いてあるので、今はこの方法は試していません。
サムネイルの生成に失敗する
古いバージョン2021年頃?のfessではサムネイルの生成がおかしかったのですが、現在のバージョンでは期待する動作をしています。
運用
縦書きPDFの検索
うちの環境依存なのかもしれませんが、縦書きPDFファイルの検索がうまくできません。利用しているOCRツールのせいなのか、そういう仕様なのか。PDFビュアーでも検索できたり、できなかったりします。
具体的には、縦書きPDFにOCR処理をした透過PDFに埋め込まれる文字の間にスペースが挿入されてしまうのです。opensearchに保存されている文字列を観察してみるとよくわかります。
Webを検索してみても情報が見つからず、苦肉の策、力業で運用できているのでご紹介します。きっと識者ならばもっと良い解決法をご存知なのでしょうね。
縦書きPDFファイルに命名規則を適用する
fessのラベル機能を利用したいので、正規表現で引っかけやすく、普通にファイル名を付ける場合と競合しないことが大切です。
うちでは、ファイルの最後に _v_ を付けることにしました。
こんな感じです
|
1 2 3 4 5 6 7 8 9 10 11 |
$ ls -1 2004_ダン・バースタイン_ダビンチコードの真実_v_.pdf 2006_ダン・ブラウン_ダビンチコード_01_v_.pdf 2006_ダン・ブラウン_ダビンチコード_02_v_.pdf 2006_ダン・ブラウン_ダビンチコード_03_v_.pdf 2010_ダン・ブラウン_ロスト・シンボル_01上巻_v_.pdf 2010_ダン・ブラウン_ロスト・シンボル_02下巻_v_.pdf 2013_ダン・ブラウン_インフェルノ_01上巻_v_.pdf 2013_ダン・ブラウン_インフェルノ_02下巻_v_.pdf 2018_ダン・ブラウン_オリジン_01上巻_v_.pdf 2018_ダン・ブラウン_オリジン_02下巻_v_.pdf |
縦書きPDFファイルにFessでラベルを付ける
fessにはドキュメント分類の為にラベルを付ける機能が実装されています。想定されている使い方としては異なるかもしれませんが、ラベルの値はopensearch内に書き込まれますから縦書きPDFファイルを判別するために利用します。
先の縦書きファイルの命名規則を「対象とするパス」に正規表現で記述して縦書きファイルに verticalという値を付与します。
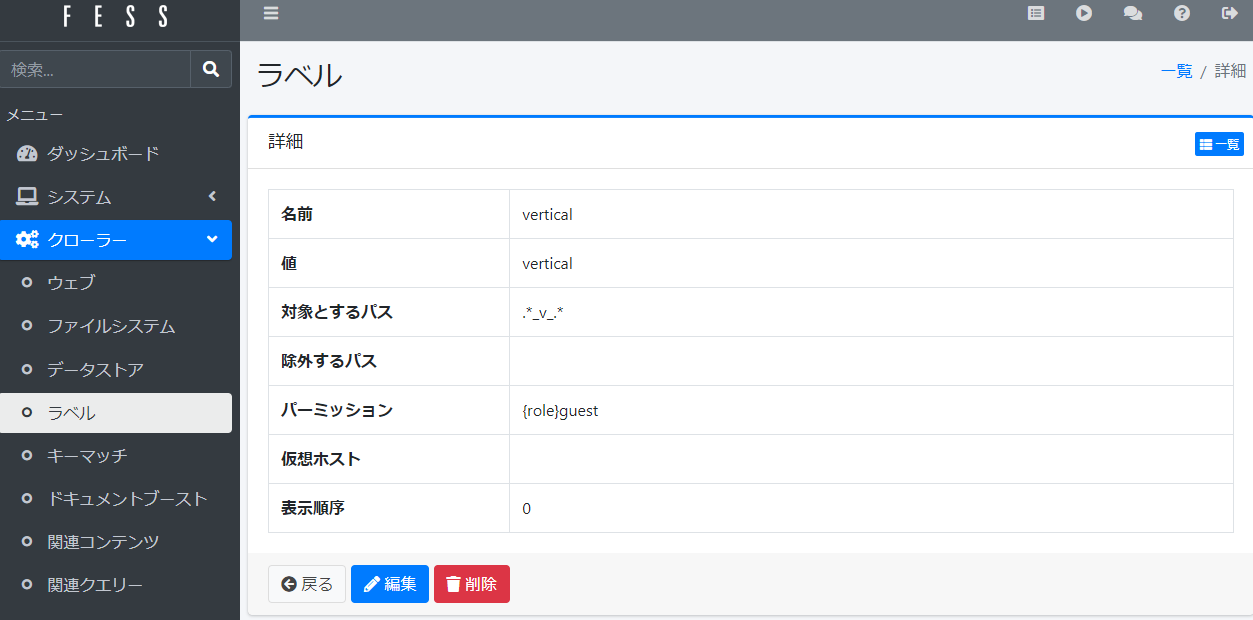
opensearch内にある縦書きPDFのテキストからスペースを削除する
いささか乱暴すぎる処理ですが、これくらいしか思いつかなかったので。opensearch内の文字列を直接読むわけではないので、これでよしとしました。
スペースの削除はpythonスクリプトで行っています。fessの定期クローラが動いた後に走るよう、適当な時刻にcronから起動しています。
idx_nameはfessのindexファイルで起動した日付で作成されます。個々の環境で異なりますので、正しいindex名に書き換えてください。
opensearch-pyとopensearch-dsl モジュールを利用しています。pipなどで導入してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
from opensearchpy import OpenSearch from opensearch_dsl import Search import re idx_name = 'fess.20240423' result_size = 5000 query = { "query": { "bool": { "must": [ { "term": { "filetype": "pdf" } }, { "term" : { "label": "vertical" } } ] } } } osc = OpenSearch( hosts = [{'host': 'localhost', 'port': 9200}], http_compress=True, http_auth=("admin","admin"), use_ssl=False, ) res = osc.search( body = query, size = result_size, index = idx_name ) r = res['hits']['hits'] for i in r: space_deleted_str = re.sub(r' ', '', i["_source"]["content"]) filename = i["_source"]["filename"] idn = i["_id"] print(filename) osc.update(index=idx_name, id=idn, body={'doc':{ 'content': space_deleted_str}}) # print(title) |
うちでは 04:00 に Fess のクローラが走ります。Fessのクローラがまっさらな状態からすべてのファイルを処理するのに90分くらいかかるので余裕をみて 06:00 にこのスペース削除スクリプトを実行させています。
apache2でのリバースプロキシ設定
Fessを直接外部へ晒さず、リクエストはapacheで受けます。既存のVirtualHostへProxy設定を追加するくらいなら、新しくVirtualHostを作成するほうが楽だしシンプルです。SSL対応も簡単です。
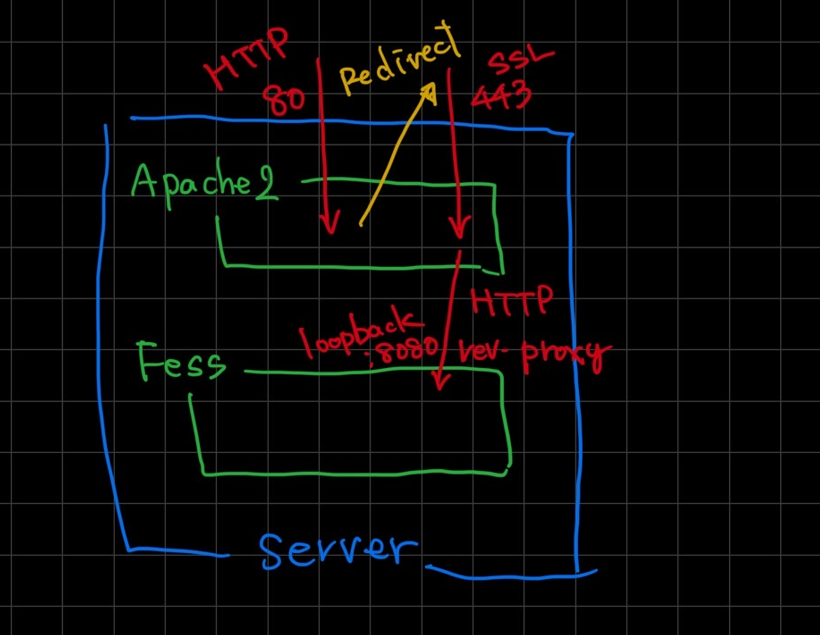
- DNSレコードを準備する
- 固定IPでない場合はDynamicDNSなどを検討
- SSL対応する場合は証明書も準備する
- apache2にvirtualhostを作成
- 受けたリクエストをlocalhostへ転送(Fessは、loopback:8080でListen)
apache2の設定の必須な箇所を抜粋
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<VirtualHost *:443> : : <Directory /path/to/document_root/> Require all denied </Directory> : : # Fess ProxyRequests Off <Location /> ProxyPass http://127.0.0.1:8080/ ProxyPassReverse http://127.0.0.1:8080/ </Location> </VirtualHost> |
注意: Fessは、検索結果から直接ドキュメントを参照できるので、外部から認証なしで検索できるような設定をするときは、apache側で認証をかけましょう。もちろん、Fess側で「システム -> 全般 -> ログインが必要」にチェックを入れるのも有用でしょう。
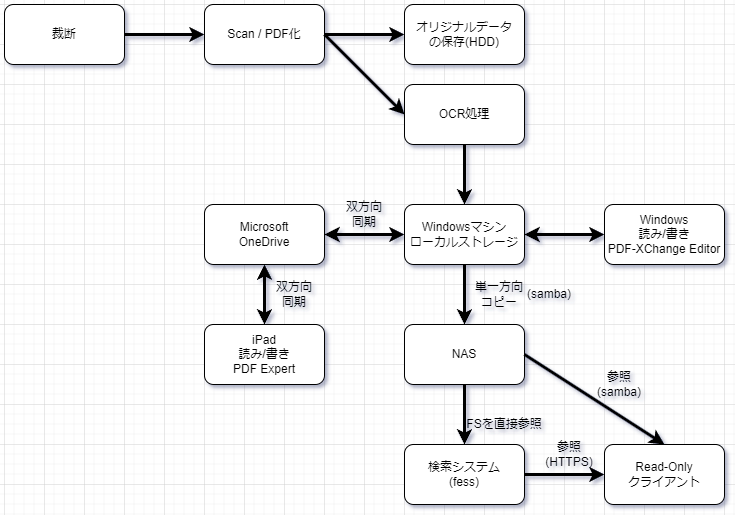
うちのデータ運用方法
- 自炊したデータは、Windowsマシン に保存する(OCR処理などが済んだもの)
- Windows から Microsoft One Drive へ双方向を同期する
- WindowsマシンからFessが参照する File system へ一方通行コピーする
- Fessが参照するFile SystemをWindowsマシン上でネットワークドライブとしてドライブレターを割り当てておけば、Robocopy.exe を使い簡単に同期ができる。
- iPadで PDF Expert の One Drive を同期フォルダ指定し、オフライン状態でも Read / Write を可能にする
- ネットワークに接続したときに One Drive と双方向同期を行い、オフライン状態時の更新を同期する
- One Drive へ同期された変更は Windowsマシン上へ自動で同期されるので、(2)の操作を実施
ユースケース
通勤時にiPadでPDFを読み書きする
通勤電車内ではiPad上のPDF Expert で自炊ファイル読みながらメモを書き入れる。高速なWiFiが利用できる環境に来たらPDF Expert で One Driveへ更新されたファイルの同期を行う(帰宅後の自宅でも可)。帰宅後 Windowsマシンから Fess側のFile Systemへ同期を実施。
新しい本をスキャンした
OCR処理が完了したPDFファイルが出来上がったらWindowsマシンのOne Driveフォルダへコピーをする。データはOne Driveと同期される。高速なWiFiが使える環境下にあるiPadでPDF Expertを起動しOne Driveとフォルダを同期する。WindowsマシンでFessが参照するFile Systemへコピー(Robocopy.exe)
Windows上で自炊PDFファイルを読みながら書き込む
Windows上のOne Drive フォルダ内のPDFファイルを直接 PDF Exchange Editorで開く。付箋やブックマークなどの書き込みが発生したら、自動で One Driveへ同期される。更新した自炊PDFファイルをFessが参照するFile Systemへコピー(Robocopy.exeで全体を同期)最後にiPadのPDF ExpertでOne Driveからファイルを同期する。
蛇足
OneDriver → iPadへの同期は結構時間がかかります。最近のWiFiは速いとはいいつつも有線に勝るものなし。ぼくは同期の時だけ iPadを有線接続しています。WiFiよりも安定しているのがいいですね。