
国会図書館をご存知でしょうか?利用したことはありますか?
国会議員の先生方をサポートするために作られた図書館なのですが、日本国籍を持つ成人なら誰でも利用することが可能です。
※入館時に免許証等の身分証が必要です。
国会議事堂の北側にあって、最寄り駅は永田町駅です。詳しくは、国会図書館のHomePageのアクセス案内をご覧下さい。
また、日曜祝日は休館日なのでご注意を。
普通の図書館とちょっと違う
「図書館」といっても近所にある地方行政が運営している図書館とは違っていて、ほとんどが閉架図書で、どちらかというと大学図書館をイメージしてもらうと近いかもしれません。基本的に
- 閲覧を希望する図書を端末で検索する
- 閲覧申請を行う
- 書庫から上がって来るのをしばし待つ
これでやっと閲覧する事ができます。もちろん個人への貸出しは行っていません。
館内で読むだけ?と思われるとかも知れませんが、読むというより資料を探しにいき、必要な箇所があれば複写サービスを利用するといった感じです。
※ 図書のみならず雑誌も、もちろん大切な資料として保管されています。
以前のぼくにとっては、利用価値がイマイチ分かりませんでした。が、しかし、砂金採取や埋蔵金に興味を持ちはじめてからは、古い鉱山の資料や絶版となり入手困難な資料などを閲覧したくて度々訪れています。
今の職場は最寄駅が霞ヶ関なので午後半休を取ればすぐに行く事が可能なのです!ただし、端末で書籍を検索後、閲覧を申し込み、手元に希望の資料が届くまではかなり待たされますから事前にめぼしい資料をインターネット経由で検索してから訪れないとあっという間に閉館時間を迎えてしまうことになります。
資料のスキャンデータが公開されている
国会図書館では、10年ほど前から資料のデジタル化作業が進み、端末上で閲覧できる資料数もかなり増えてきました。デジタル化されている資料は、著作権の関係上、3種類のデータに分かれています。
-
- 著作権が切れている、またはインターネット公開が許可されている図書
- 国立国会図書館/図書館送信限定
- 国立国会図書館限定
インターネット上で閲覧できる資料は限られており、国会図書館の館内若しくは提携図書館の指定端末でのみ閲覧可能な資料はかなり多い。というのが現状です。これから徐々に増えていくと思いますし、少量だとしてもインターネット上で見られるのはありがたいことです。
先日仕事の隙間時間にホームページを訪れてみると、お知らせの所に「コンテンツ閲覧画面に全コマダウンロード機能を追加しました」と書かれているではありませんか。以前はページの多い図書をPDF化して一気にダウンーロードする事はできませんでした。だいたい、40ページくらいで分割しないとPDF変換エラーになり、かなり使い勝手が悪かったのです。
おお?っと、試しにダウンロードをしてみるとちゃんと1ファイルとして落ちてきました。これなら通勤時間にタブレットで読むのに良いなぁとページ内をうろうろしていると、「国会図書館ではオープンデータとしてデジタルコレクションのタイトルリストを公開している」の気づきました。
オープンデータとは
総務省が説明しているオープンデータの為の条件によれば
- コンピュータで再利用しやすい形式であり
- 二次利用が可能な利用ルールが定められていること
とあります。wikipediaや国立国会図書館のLODでもだいたい同じ事が書かれています。
最近になって公共機関などからオープンデータとしていろいろな情報が公開されていますが、formatがexcel, HTML, PDFと、公開している機関によって形式はまちまちだったりします。
そのあたり国会図書館は使いやすいexcel形式とtsv(Tab Separated Values)形式でデジタルコレクションのタイトルリストを提供していて好感が持てます。
デジタルコレクションの一覧リストは、こちらでダウンロードできます。
どう使うか?
Excel形式が用意されているので、Excelをお持ちの方ならそのまま検索できるのかな?ぼくはExcelがどうも苦手なのと自宅PCにはExcelをインストールしていないので、データベースへTSV形式のデータを突っ込んでみました。
展開したTSV形式データは、73Mバイト, 35万行程度の大きさです。
|
1 2 3 4 5 6 7 |
% du -hs ./dataset_201803_t_internet.tsv 73M ./dataset_201803_t_internet.tsv % wc -l ./dataset_201803_t_internet.tsv 351604 ./dataset_201803_t_internet.tsv |
フィールドにはよく分からないものあるのだけれど、とりあえずテキトーにvchar()でテーブルを作ってみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
create table ndl_t_internet ( id int auto_increment, url varchar(255), title varchar(255), volume varchar(100), series varchar(100), version varchar(100), author varchar(255), publisher varchar(255), year varchar(255), isbn varchar(100), size varchar(100), scope varchar(100), ndc varchar(100), ndc_8 varchar(100), ndc_9 varchar(100), ndlc varchar(100), ndlsh varchar(100), index (id) ) DEFAULT CHARSET=utf8; |
さて、ここにデータをインポートして行くのですが、1行ずつ処理していると何時間もかかってしまいそうなので、1000行単位でインポートするようにしてみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
#!/usr/bin/env python #coding: utf-8 # for python3.x # required mysql connector module # pip install mysql-connector-python-rf import sys import csv import mysql.connector count = 0 records = 0 max = 1000 values= '' SQL = 'INSERT INTO ndl_t_internet(url, title, volume, series, version, author, publisher, year, isbn, size, scope, ndc, ndc_8, ndc_9, ndlc, ndlsh) VALUES ' def make_conn(): conn = mysql.connector.connect( host = 'localhost', port = 3306, user = 'root', password = 'xxxxxxxxx', database = 'ndl_index', ) conn.ping(reconnect=True) return (conn) conn = make_conn() cur = conn.cursor() # read from stdin reader = csv.reader(sys.stdin, delimiter = '\t') _ = next(reader) # make a query per 1000 lines. for s in reader: count += 1 values = values + "('{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}'),".format(*s) if count >= max : query = SQL + values.rstrip(',') + ';' cur.execute(query) conn.commit() records += count print("Insert Records: {}.".format(records)) count = 0 values = '' query='' else: query = SQL + values.rstrip(',') + ';' cur.execute(query) conn.commit() records += count print("Insert Records: {}.".format(records)) |
コードを見ればわかるように、cvs.reader()で標準入力から一気に読み込み、1000行単位でループを回します。1000レコードがくっついた巨大なSQL文を作成し、一気に1000カラムをinsertしています。こうすることで、実行時間を大幅に短縮する事が可能です。35万行を処理するのに1分もかかりません。標準入力を使わずに直接ファイルオープンすればもっと時間短縮できそうですが、標準入力からいれる方が応用が利くのでこうしています。
|
1 2 3 4 5 6 7 |
mysql> select count(*) from ndl_t_internet; +----------+ | count(*) | +----------+ | 351603 | +----------+ 1 row in set (0.32 sec) |
無事にデータのインポートが完了しました。
検索しまくり
MySQLのofficial pageで配布されているclient(MySQL Workbench)がとても使いやすいので、それを使って検索しまくってみます。
今回使うDBを選択してから、適当なSQLを発行してみます。
|
1 2 3 4 5 6 7 8 9 10 |
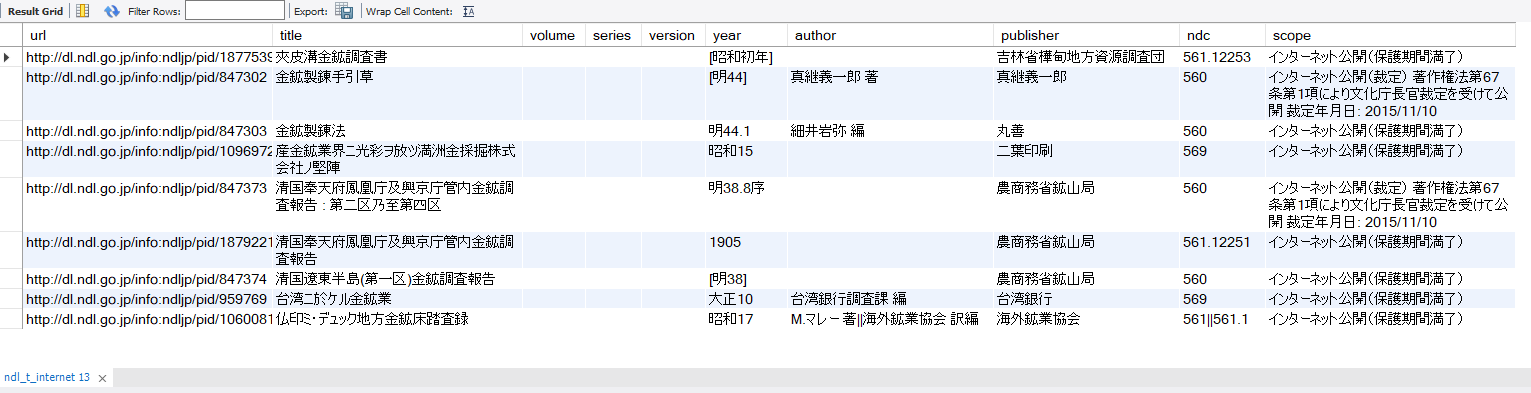
# # 図書 # select url, title, volume, series, version, year, author, publisher, ndc, scope from ndl_t_internet where title like '%金鉱%'; select url, title, volume, series, version, year, author, publisher, ndc, scope from ndl_t_internet where title like '%金山%'; select url, title, volume, series, version, year, author, publisher, ndc, scope from ndl_t_internet where title like '%埋蔵%'; select url, title, volume, series, version, year, author, publisher, ndc,scope from ndl_t_internet where title like '%鉱山%'; select url, title, volume, series, version, year, author, publisher, ndc,scope from ndl_t_internet where title like '%鉱山%' and title like '%東京%'; select url, title, volume, series, version, year, author, publisher, ndc, scope from ndl_t_internet where title like '%秩父%'; select url, title, volume, series, version, year, author, publisher, ndc, scope from ndl_t_internet where ndc like '%560%'; |
するとこんな感じに、結果が一瞬で表示されます。
 よく拝見させてもらっているblog(砂金に魅せらて! 金狼の日々 (きんろうのひび))で、先日、山相秘録が紹介されていました。
よく拝見させてもらっているblog(砂金に魅せらて! 金狼の日々 (きんろうのひび))で、先日、山相秘録が紹介されていました。
さっそく、検索してみるとありますね。
|
1 |
select url, title, volume, series, version, year, author, publisher, ndc, scope from ndl_t_internet where title like '%山相%'; |

内容をみてみましたが、ぼくにはちょっと読めなさそうな本でした ><




