全く知らなかったのですが、国立国会図書館デジタルコレクションに収蔵されている資料を全文検索できるシステムが NDL Labで試験公開されています。(※ OCR済みの書籍約26万点が対象だそうです)
昔、デジタル化された資料リストを自宅のMySQLに突っ込んで検索できるような事をしてしいましたが、タイトルやメタデータだけではやっぱり漏れるんですよね。
さっそく使ってみる
次世代デジタルライブラリーにアクセスし「全文から検索する」ボタンを押すと、シンプルなUIが現れます。後は、検索したい文字列を入力するだけ。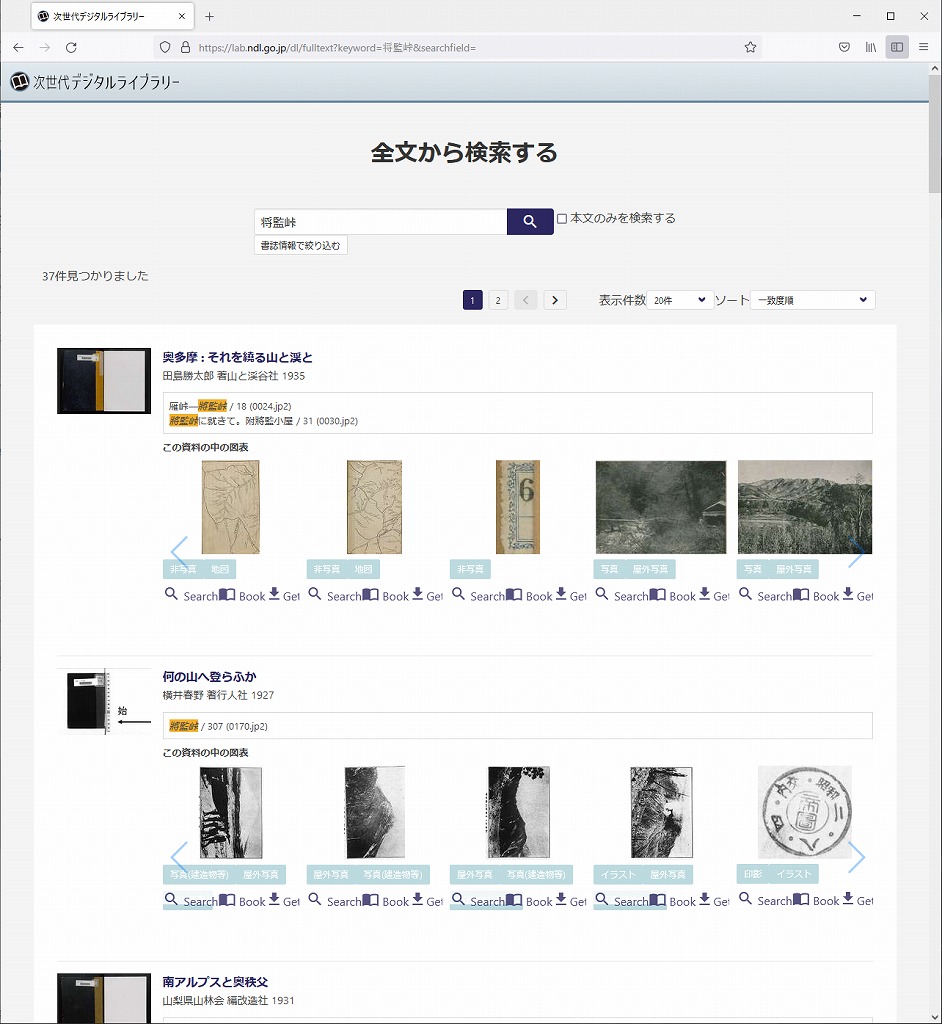
ここでは「将監峠」と入力しています。通常、将監峠は奥秩父に含まれるので「奥多摩..」というタイトルの本は今までスルーしていました。しかし、全文検索ならば気づくことができるのですね。素晴らしい。簡単に検索をかけただけで、今まで読んだことのない資料が何冊も見つかりました!
このNDL Labの全文検索システムに登録されている資料は、著作権が切れているのでPDFでダウンロード可能です。ただし透明テキスト付きPDFではないので、PDFビューアでは内容を検索できないのが残念です。OCRしたテキストデータはダウンロードできますが、ただのテキストデータなので、どのように組み合わせたら良いのかわからんです。
ダウンロードしたテキストデータとPDFファイルを結合させて透明テキスト付きファイルにして、自宅内に構築している全文検索システムに放り込みたいんですけどー





